数据中心网络 CLOS网络
在传统的大型数据中心,网络通常是三层结构。Cisco称之为:分级的互连网络模型(hierarchical inter-networking model)。这个模型包含了以下三层:
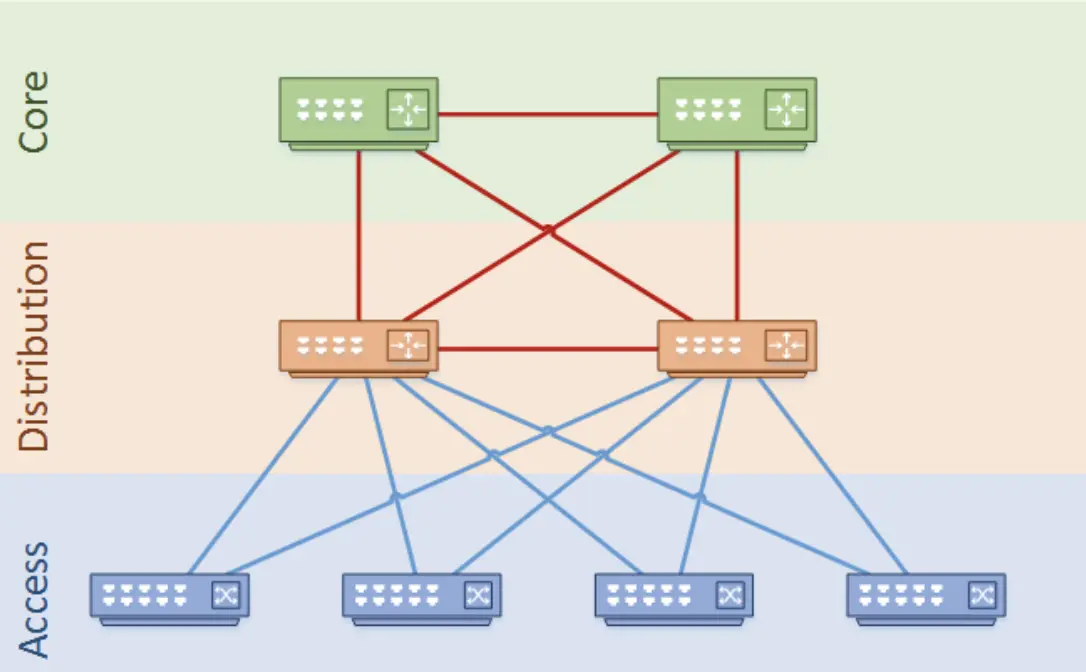
Access Layer(接入层):在局域网中,接入层提供终端设备接入网络的功能;在广域网中,它可能还提供远程办公( teleworker)或远程 site 通过 WAN 访问公司网络的功能。
Distribution Layer(分发层):分发层对接入层的包进行聚合(aggregate),然后送到核心层进行路由。分发层是 L2 网络(交换)和 L3 网络(路由)的边界。
Core Layer(核心层):核心层也称作网络骨干(network backbone),由高速网络设备组成。核心层设计用来尽可能快地转发包,以及互联多个网络模块 ,例如分发模块、服务模块、数据中心,以及 WAN 边缘。
传统三层网络架构的规模取决于核心层设备的性能和规模、交换机的端口密度。最大的数据中心对应着体积最大和性能最高的网络设备,这种规模的设备并非所有的网络设备商都能提供,并且对应的资金成本和运维成本也较高。采用传统三层网络架构部署数据中心网络,企业将面临成本和可扩展性的两难选择。
一、现代数据中心网络的需求
数据中心的诞生是为了服务于数字业务,因此,它需要适应每一个阶段业务的架构和需求。前两次应用业务架构为单体应用程序(monolithic single-machine applications)以及客户端-服务器(Client-Server)架构模型。然而,随着云计算的兴起,越来越多的业务应用架构转变为了服务器-服务器(Server-Server)模式。这也是第三次应用浪潮,它的出现,也让承载它的数据中心架构发生了巨大的变化。此变化需要对下面三项提供良好的支持:
对服务器-服务器通信需求的增加:
在客户端-服务器架构中,物理服务器一般仅仅处理客户访问自己的请求(Request),或者与一些特定的服务器通信,例如数据库。但总体来说,大部分流量依然是南北向(South-North)流量。相反的是,目前的一些应用,例如Hadoop,需要部署在数以百计的节点上,并且无缝通信。这需要极大的东西向(East-West)流量支持。进一步说,现在的服务器为了提供更优秀的东西向流量支持、可移植性、可拓展性以及更高的硬件利用率,放弃了物理服务器直接部署应用的方式,而是转为了以虚拟机(Vitual Machine)或者微服务(Microservices)架构的形式。这种新的服务器部署形式对网络架构的要求是之前数据中心无法支持的。
规模:
随着数据储存量和计算能力的极大攀升,数据中心的规模也不断的扩大,通常一个数据中心需要上万以及数十万的服务器进行支持,而以往数据中心的网络架构通常无法满足如此庞大的服务器接入。
恢复力(Resilience):
数据中心网络的规模的增大必然带来网络故障出现频率变多。传统的数据中心通常使用向内扩张(Scale-in)的方式,使用更昂贵复杂的设备来来提高数据中心性能。但是这种方式导致设备一旦出现故障,所辐射的用户范围将变大,并且难以排错,这是业务所无法忍受的。所以在新的数据中心架构设计中,它被允许能够出现故障,但是要求故障是可控的(范围小),易于排错和快恢复,以及对用户影响十分微小的。
因此,未来解决上述问题,Clos架构被应用于来新的数据中心网络中。
二、Clos模型架构
Clos架构模型在上世纪50年代就已经被理论提出,以应对爆炸式的网络增长。图1显示了最简单的Clos模型。其中,方框节点代表交换机,灰色节点代表服务器。在方框节点中,顶部是Spine节点,下部是Leaf节点。Spine节点与Leaf节点相互连接,每片Leaf都连接到每个Spine节点,反之亦然。此外,Leaf节点下连服务器,为服务器提供网络接入服务。
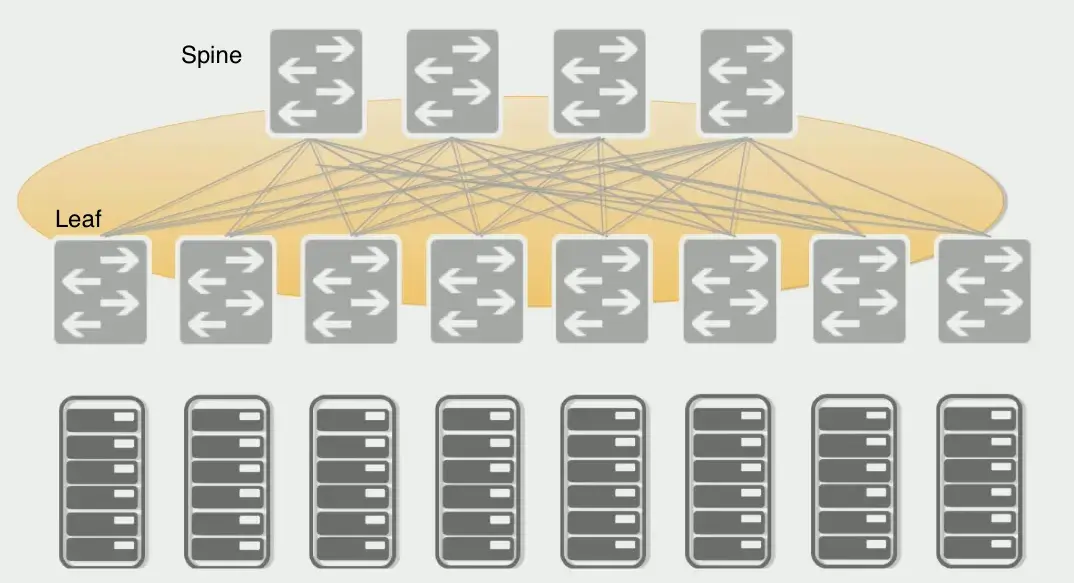
图1:2层Clos架构
进一步说,这样的模型架构有如下的好处:
首先要注意的是连接的统一性:服务器通常距离任何其他服务器只有三跳,网络质量容易保证。
接下来,节点非常均匀:服务器看起来相似,交换机也是如此。这种重复的网络结构就像一个一个模块堆积而成,满足了现代数据中心快速,简单的拓展对需求。
第三,根据现代数据中心应用程序的要求,连接矩阵(Matrix)相当丰富,使其能够优雅地处理故障。可以看到,每一个Spine和Leaf节点都有线路连接,其中一条或者多条链路故障对整个网络对影响不大。
此外,我们可以看到,所有服务器直接与Leaf交换机直接相连,Spine只是作为连接器来完善服务器之间的连接。在这个模型中,服务器被推到Leaf,而不是Spine。这种架构模型称为向外扩张(Scale-out)模型。在实际的部署中,服务器通过低速链路与Leaf互连,交换机之间通过高速链路互连。
想要对该模型架构进行扩容,通常有两个方法。一个是增加Leaf和Spine节点的数量、更换更好的设备以及接口转发速率,但是这种方式很容易受到每个交换机接口数量,投入成本以及转发效率的限制。还有一种方式则是增加Clos网络的层级,例如从二层Clos网络转变为三层Clos网络架构,如图2所示:
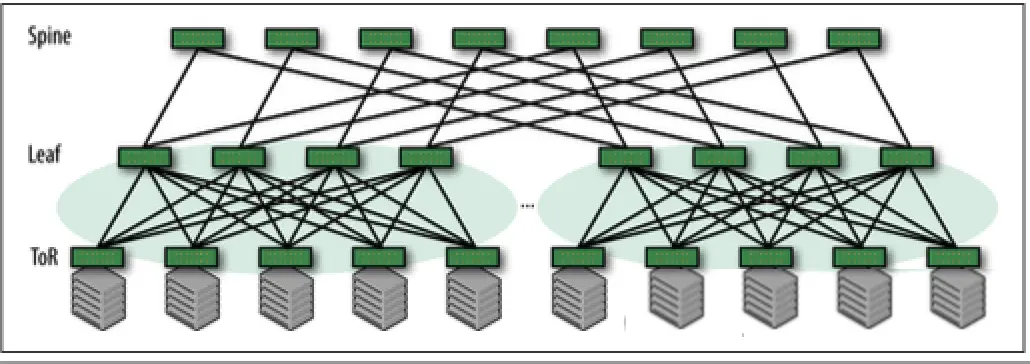
图2:3层Clos架构
可以看到,整个网络分为了三层,分别是Spine、Leaf和Tor(Top of rack)。其中Tor设备也就是整个网络服务器的接入点,由于它通常部署在每一个Rack的顶端,所以被称为Tor of rack。由于多个Leaf和Tor组成的二级Clos网络通过Spine进行连接,极大的扩张了数据中心设备的规模。这从根本上展示了Clos网络的美妙之处:就像分形设计一样,更大块都是从本质上相同的积木组装而成的,每一个积木并不需要有超强的转发能力。甚至我们可以将网络层级扩大到四级或者更多,以绕过较小构建块的规模限制。
最后总结一下,通过扩大层级的方式,我们使用固定的,相对廉价的交换机就能过建成规模庞大的网络。同时受益于每一层级间丰富的互联的链路,及时链路乃至设备出现故障,所损书的带宽依然在可控范围内,并且所影响的服务器不多(传统网络中通常两台设备做备份,其中一台出现故障,带宽直接减少百分之50)。最后,由于交换机以模块化的形式部署,我们只需要选择几类不同型号的即可,方便管理和排错。
三、Clos网络架构
Clos网络架构还要求使用与传统网络架构不同。在传统网络中,我们所谓的Spine层被称为网络的访问聚合层。前两层网络是使用桥接(bridge)而不是路由(routing)连接的。桥接网络中使用生成树协议(STP),该协议将Clos网络的丰富连接矩阵分解为无环路树。例如,如图1所示,在双层Clos网络中,最左边的叶子和最右边的叶子之间有四条路径。然而,STP只能使用其中一条路径。因此,对于左边和最右边的Leaf,拓扑缩减为图3所示的拓扑结构。

图3:STP协议下的Clos架构
相比来说,路由能够充分利用Clos网络的丰富连接矩阵,利用所有路径。路由还可以采用最短的路径,以更好地整体链路利用率。因此,我们可以得到如下的结论,路由最适合Clos结构,而桥接则不适合。从桥接到路由的转换中获得的一个关键好处是,我们可以摆脱桥接网络所需的多个协议,其中许多是专有的。传统的桥接网络通常运行STP、VLAN协议、第一跳路由协议(如主机备用路由协议(HSRP)或虚拟路由器冗余协议(VRRP)),以及路由链路的单独单向链路检测协议。通过路由,我们唯一的控制平面协议是路由协议和双向链路检测协议(BDF)。通过减少运行网络工作所涉及的协议数量,我们还提高了网络的弹性和减少了排错的复杂性。
四、服务器接入模型
大型企业的数据中心拥有丰富的服务器,因此因网络工作故障而损失整个机架无关紧要。然而,在许多较小的网络中,由于失去一个Tor会导致整个机架的服务器无法使用,并且无法承担该后果。因此,它们双连接服务器,每个链接都连接到不同的ToR,并且这两个ToR都位于同一个机架上。
因此,当服务器双连接时,双链路使用供应商专有协议聚合成单个逻辑链路,Cisco称其为虚拟端口通道(vPC),Arista称其为多机箱链路聚合协议(MLAG)等等。从协议的角度来看,连接到服务器的两个交换机提供了一种错觉,即它们是单个交换机。此外,两台Tor之间还需要通过标准的链路聚合控制协议(LACP)协议捆绑链路,以提高互联接的可靠性。图4显示了带有MLAG的双连接服务器架构。
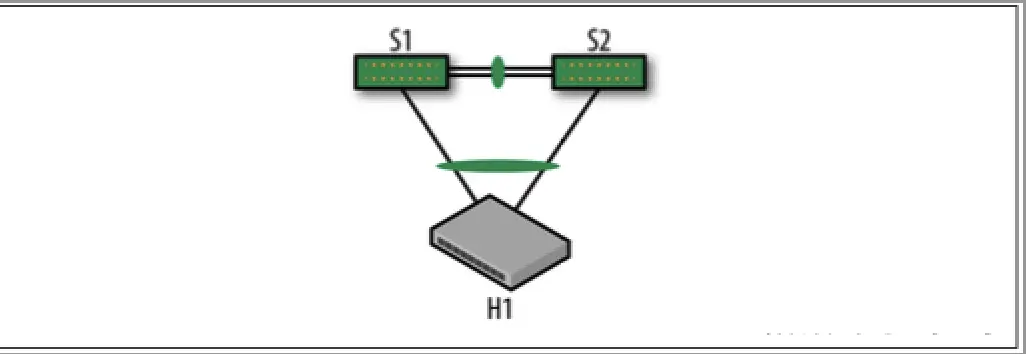
图4:双上行服务器接入模式
五、连接外部网络
Clos网络访问外部网络通常有两种方式,分别是通过Border pod或者Spine。它们的架构图分别如图5和图6所示:
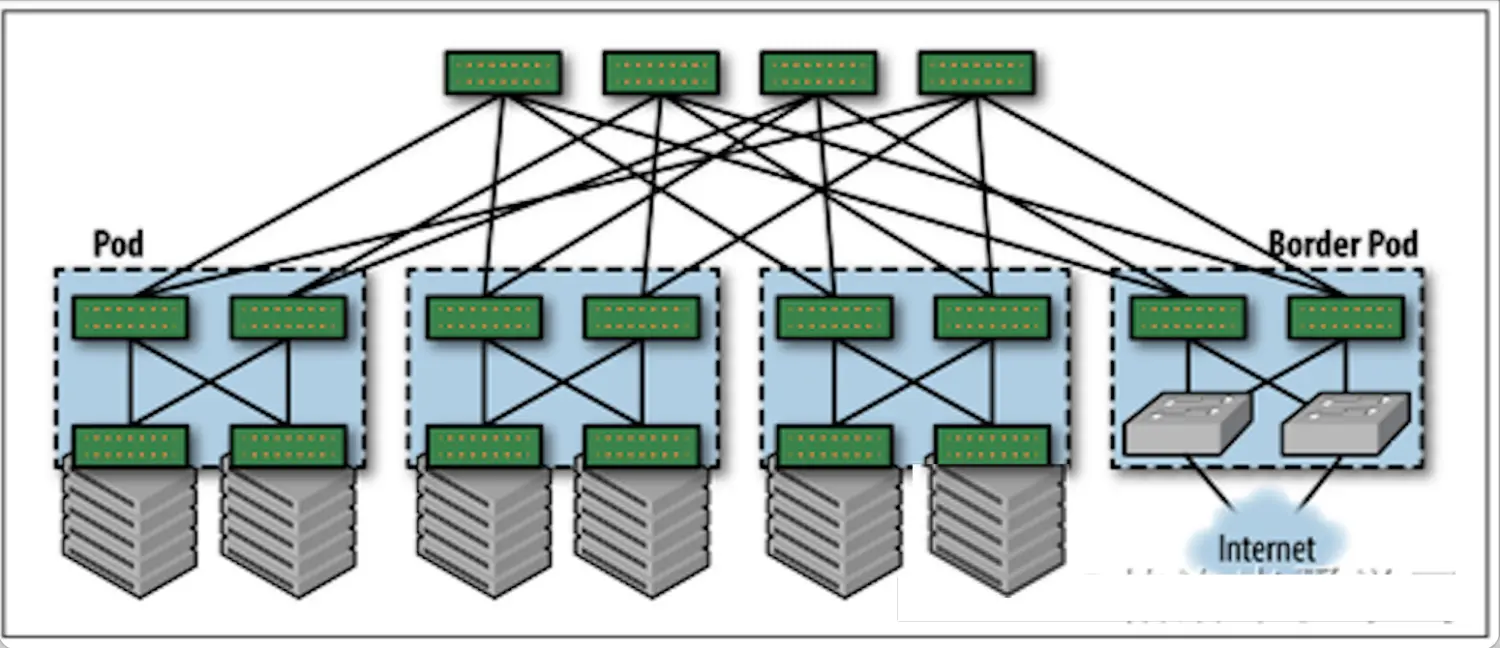
图5:通过Border Pod访问外网
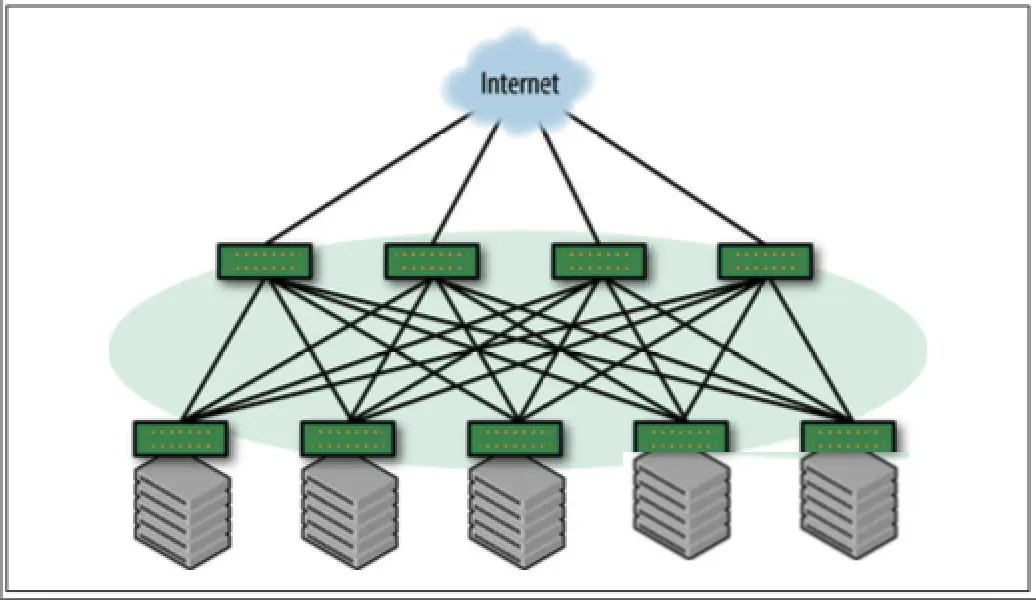
图6:通过Spine访问外网
简单来说,这两种模型各有优势。首先是通过Border Pod访问外部网络,这种方式最大的优势就是将内部网络和外部网络进行了分离,内部的路由协议不会和外部进行交互,保证了内部网络的稳定和安全性。但是,如果是在小规模的网络中,通常是没有成本去专门部署Boeder Pod的,因此也可以直接通过Spine实现对外网的访问。需要注意的是,在这个模型中,所有Spine都需要连接到外部网络,以实现流量的负载(ECMP),否则所有流量仅通过少数的Spine访问外网,会照常相应的链路拥塞和设备故障。
六、支持多租户
随着云计算的兴趣,数据中心的网络还需要满足一些额外的特征:
敏捷性:鉴于云的典型使用,即客户快速创建和删除资源,网络能够支持这种模式至关重要。
隔离:一个客户的流量不得被其他客户看到。
规模:必须支持大量客户或租户。
相对来说,传统的数据中心架构通过VLAN、VPN实例来隔离租户已经不适用于虚拟机以及微服务的架构场景,因为VLAN和VPN实例无法实时的感受这些服务的创建和销毁,此外VLAN ID的个数(1-4095)也极大程度限制了数据中心所能连接服务器的数量。因此,通过Clos架构在底层(Underlay)运行路由协议保证网络全局可达的情况下,再通过虚拟拓展局域网(VXLAN)的方式在租户间建立VXLAN的高层(Overlay)隧道,能更好的解决支持多租户的问题。
七、自动化运维需求
由于数据中心的规模巨大,我们必须对其采用自动化的管理形式。如果一个数据中心中设备各异,差别巨大,是几乎无法实现全自动化管理的。庆幸的是,在Clos架构中通常使用的交换机类型固定,并且通过VXLAN结合软件定义网络(SDN)的形式,能过极大的简化网络部署和运维的压力。
八、路由协议选择
这里我们推荐使用BGP来架构数据中心的底层网络。相对于OSPF,它天生支持更多的协议栈(OSPFv2和OSPFv3严格来说是两个不同的协议),并且BGP也不需要向链路状态协议定时泛洪链路(Link-State)状态信息,因为BGP是基于触发更新,以减少路由协议对带宽的消耗。此外,通过BGP的形式传递路由,交换机也无需维护极大的链路状态数据库,减少对于宝贵计算资源的浪费。另外一点,BGP带有更加丰富的选路属性,能过灵活的帮助数据中心实现底层的网络负载均衡等需求。最后,BGP是基于TCP协议同步信息,有足够的可靠性。
当然BGP的收敛速度一般是无法与链路状态协议所相比的。并且,BGP作为一种特殊的距离矢量(Distance- Vector)协议,也有着所有距离矢量协议的通病。因此,我们需要对BGP进行一些额外的调试,以解决这些问题。
Facebook Fabric Datacenter
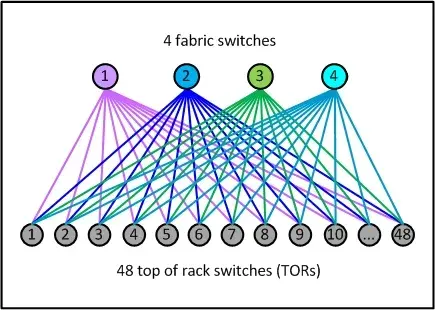
Fabric网络架构最具有代表性的就是Facebook在2014年公开的其数据中心架构:Introducing data center fabric, the next-generation Facebook data center network。Facebook使用了一个五级Clos架构,前面说过实际的网络设备即是输入又是输出,因此五级Clos架构对折之后是一个三层网络架构,虽然这里也是三层,但是跟传统的三层网络架构完全是两回事。对应于上面介绍的架构,Facebook将leaf交换机叫做TOR,间添加了一层交换机称为fabric交换机。fabric交换机和TOR构成了一个三级Clos结构,如下图所示,这与前面介绍的spine/leaf架构是一样的。Facebook将一组fabric交换机,TOR和对应的服务器组成的集群称为一个POD(Point Of Delivery)。POD是Facebook数据中心的最小组成单位,每个POD由48个TOR和4个fabric交换机组成,下图就是一个POD的示意图。
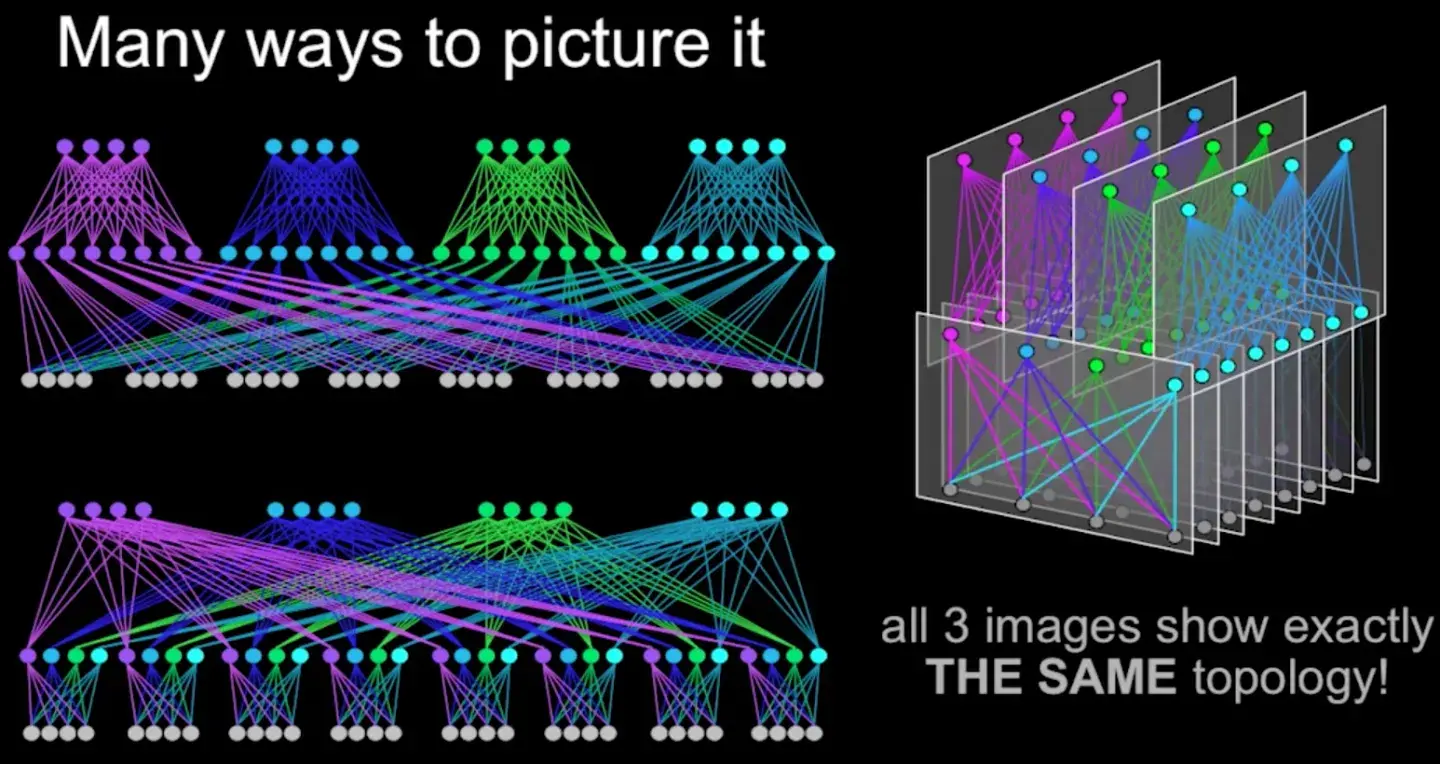
在Facebook的Fabric架构中,spine交换机与多个fabric交换机连接,为多个POD提供连通性。其整体网络架构如下图所示。下图中用三种方式表示了同一种网络架构。最上层是spine交换机,中间是fabric交换机,最下面是TOR。
在Fabric架构中,存在着两个切面,左右切面是一个个POD,前后切面被称为Spine Plane。总共有4个Spine Plane,每个Spine Plane也是一个三级Clos架构。在Spine Plane中,leaf是Fabric交换机,Spine就是Spine交换机。每个Spine Plane中,由48个spine交换机和N个fabric交换机相连组成,N等于当前数据中心接入的POD数。Spine Plane的三级Clos架构和POD的三级Clos架构,共同构成了数据中心的五级Clos架构。因为在POD内,fabric交换机通过48个口与TOR连接,所以在Spine Plane的Clos架构中,fabric交换机的输入输出端口数都是48,对应上面的公式,m1=n3=48。根据Clos架构的特性,在Spine plane中,Spine交换机只要大于等于48个,不论N(POD数)等于多少,都可以保证网络架构无阻塞。当然实际中N还受限于spine交换机的端口密度。
由于每个POD有4个fabric交换机,所以总共有4个Spine Plane。完整的架构如下图所示:
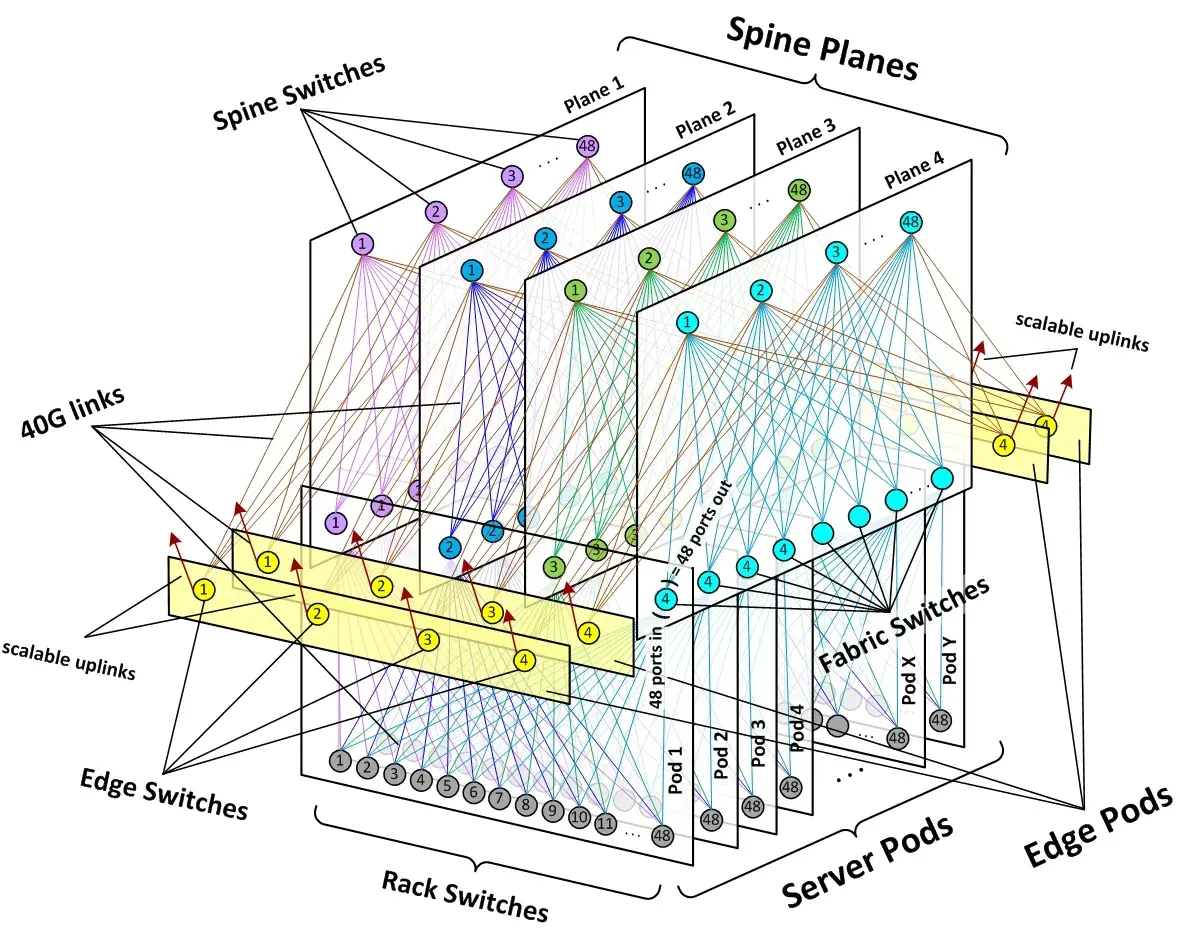
除了前面描述的POD和Spine Plane,上图中还有黄色的Edge Plane,这是为数据中心提供南北向流量的模块。它们与Spine交换机的连接方式,与二层的spine/leaf架构一样。并且它们也是可以水平扩展的。
采用Clos架构的数据中心网络架构的优势:
- 弹性可扩展。数据中心可以以POD为单位构建,随着规模的增加,增加相应的POD即可。在Spine交换机端口数可承受的范围内,增删POD并不需要修改网络架构。
- 模块化设计。不论是POD,Spine Plane还是Edge Plane,都是一个个相同的模块,在水平扩展的时候,不需要新的设计,只是将原有的结构复制一份即可。
- 灵活。当对网络带宽要求不高的时候,Spine交换机和Edge交换机可以适当减少。例如Facebook表示,在数据中心的初期,只提供4:1的东西向流量超占比,这样每个Spine Plane只需要12个Spine交换机。当需要更多带宽时,再增加相应的Spine交换机即可。同样的模式也适用于Edge交换机。这符合“小规模启动,最终适用大规模”的思想。
- 硬件依赖性小。传统三层网络架构中,大的网络规模意味着高端的核心汇聚交换机。但是在Fabric架构中,交换机都是中等交换机,例如所有的fabric交换机只需要96个端口,中等规模的交换机简单,稳定,成本低,并且大多数网络厂商都能制造。
- 高度高可用。传统三层网络架构中,尽管汇聚层和核心层都做了高可用,但是汇聚层的高可用由于是基于STP(Spanning Tree Protocol),并不能充分利用多个交换机的性能,并且,如果所有的汇聚层交换机(一般是两个)都出现故障,那么整个汇聚层POD网络就瘫痪。但是在Fabric架构中,跨POD的两个服务器之间有多条通道(4*48=192),除非192条通道都出现故障,否则网络能一直保持连通,下图是一个跨POD服务器之间多通道示意图。
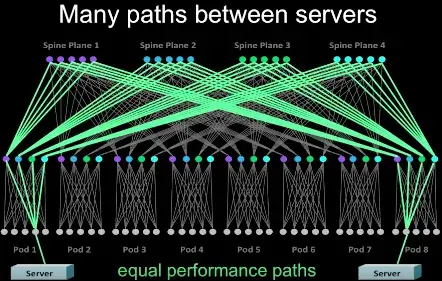
需要指出的是,这种网络架构并非Facebook独有(是不是原创无从考证),例如Cisco的Massively Scalable Data Center (MSDC),Brocade的Optimized 5-Stage L3 Clos Topology都是类似的5级Clos架构。其中一些组成元素,各家叫法不一样,不过原理都是类似的。
最后
技术发展的过程中,有一些技术提出,应用,流行,消逝,过了一段时间,在新的领域,被人又重新提出,应用,流行,这本身就是一种非常有意思的现象。Clos架构就是这么一种技术,从最开始的电话交换架构,到交换机内部模型,到现在的网络架构,它在不同的领域解决着同样的问题。
作者:程序员札记
链接:https://www.jianshu.com/p/22f1372c655c
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。