Tesla Open AI Day解读
一、前言
2021年08月20日,特斯拉在Open AI Day上介绍了最新的自动驾驶进展。视频YouTube链接、B站链接。智能驾驶三要素:安全、舒适、高效。整个介绍主要分为三个部分,第一部分视觉感知,主要是通过视觉方法实现检测、识别、分割、速度、方向的预测;第二部分规划决策,包括路径规划、转向、停车等场景下的问题决策;第三部分数据标注;第四部分数据模拟;第五部分硬件,加速芯片、DOJO、开发工具、Tesla Bot等。本文主要介绍前四部分。
二、视觉感知
背景介绍上来先给了一张图,也就是Tesla智能驾驶摒弃了激光雷达,通过全视觉方案完成智能驾驶。通过车载八个摄像头完成全方位视觉感知,映射到三维向量空间中。 后面又给出一张图,即通过神经网络的建模,来模拟大脑视觉皮层的视觉感知,这里我就贴图了。 这里要明确一下两个概念:(1)图像空间:图像拍摄的空间;(2)向量空间:在真实三维场景中,需要将所有的检测结果转换到真实的场景位置坐标中。

1、视觉感知基本框架
下图是一个视觉感知的基本框架:
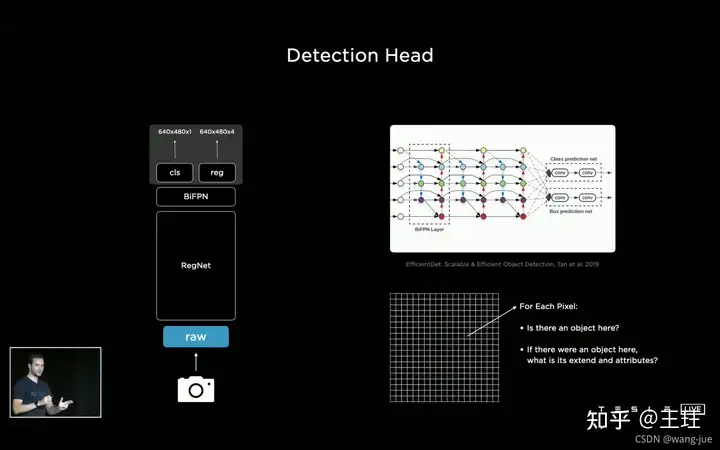
由下往上,逐层分析: (1)输入:相机输入是1280×960,12-Bit,36Hz的图像,也就是每秒36帧12位的1280×960的高清图像(这里应该是多机位的,也就是每个摄像头都是一秒36帧图像); (2)RegNet:网络的骨干网络是RegNet,来源于何凯明大神2020年的论文《Designing Network Design Spaces》; (3)BiFPN:采用BiFPN的多尺度特征融合方法,可以获得四个尺度160×120×64、80×60×128、40×30×256、20×15×512的多尺度特征图,用于感知不同尺度的目标; (4)Detection Head:这里只说了“Yolo like”的框架,应该是类似于YOLO的单阶段检测算法;最终通过输出的二进制特征图判定每个位置是否有目标以及目标的属性。
2、HydraNets
HydraNets,多任务学习的感知框架,这里多任务共享特征,同时进行多任务处理。
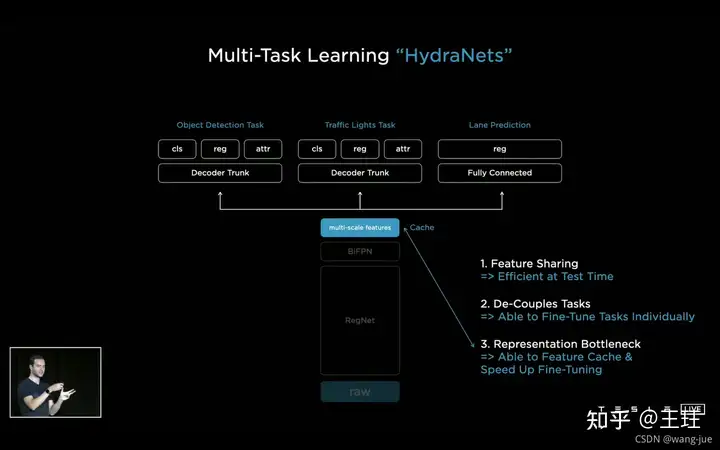
分析有三个特点,如图所示: (1)特征共享:通过backbone网络进行特征提取之后,同时可以进行多个任务的处理,提高推理效率; (2)解耦合:多个任务间互不干扰; (3)Fine-Tuning:在fine-tune时可以将backbone网络固定住,只训练检测头的参数,提高效率。
3、多角度信息融合难点
不同视角下相机的检测结果需要进行融合,以获得车辆周围的信息感知。但是有两个难点: (1)不同角度相机的检测结果难以融合,如果通过调节参数来做很麻烦(比如车辆 不同,相机安装不同都需要重新调整); (2)图像空间的检测结果与输出空间的检测结果不同。
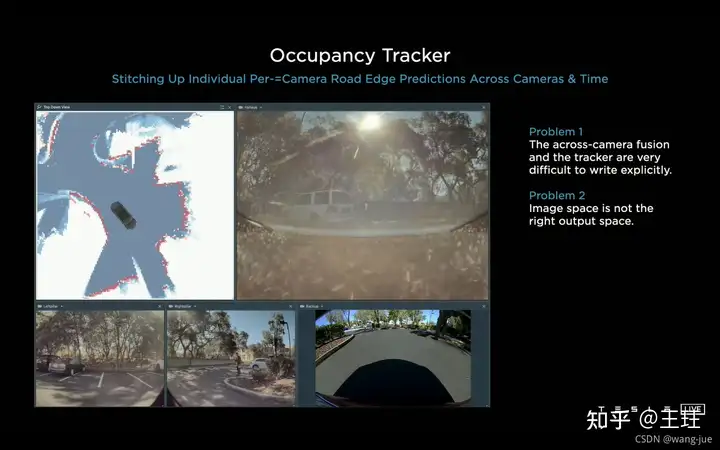
多相机的不同角度检测结果融合会导致较大的偏差,比如图像到向量空间中映射偏差、离相机距离近的特征点密集,远的离散,导致预测车道线等不连续。
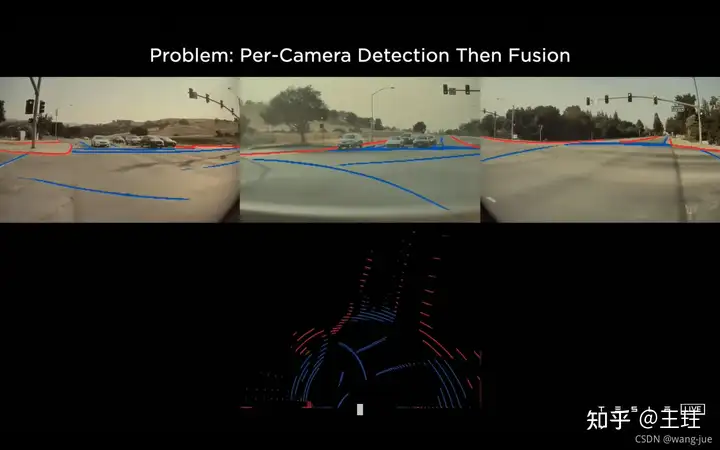
对于不同相机拍摄到的同一个目标,由于位置偏差看到的都是目标的局部信息,无法判断属于同一目标。

4、多相机向量空间预测/校准
既然每个相机预测的结果进行融合会导致很大的偏差,通过多个相机的图像的特征进行融合,然后再进行检测(也就是把多个图像特征融合在一起,最终只预测出一个结果),就能很好的解决多相机预测融合的问题。
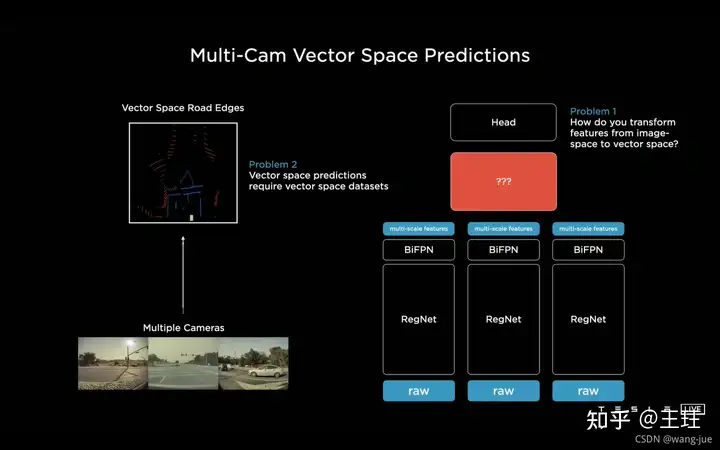
这个框架图看起来很明朗,多机位的相机拍摄到图像,经过BackBone进行特征提取,获得多尺度特征,最后送入到红色的框框中,最后完成检测。(感觉这里不同角度所用的BackBone的参数应该是不同的,相机角度不同,获得的图像也不同,比如正前方的平视与侧面的拍摄的凸面图像是不同的) 这样就会存在两个问题:图像到向量空间的转换、需要向量空间的数据。 (1)图像到向量空间的预测 通过Transformer来实现多机位特征到结果的预测,由于通过融入不同相机的位置信息,能够获得准确的空间位置映射。
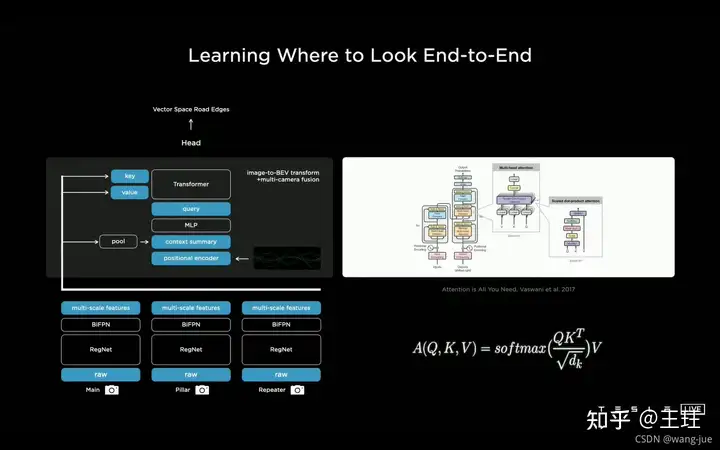
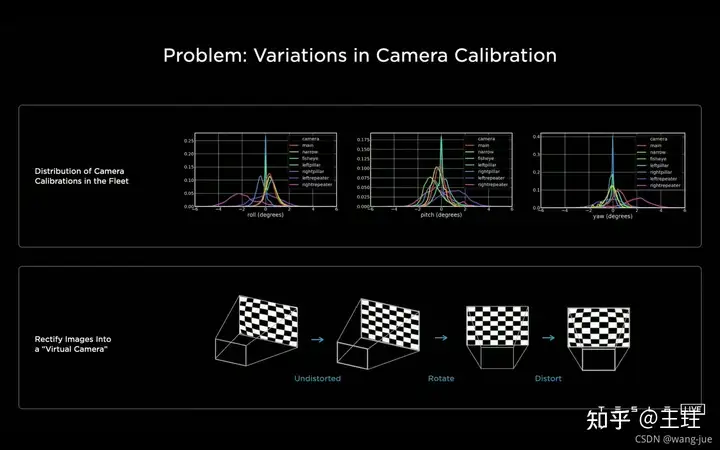
(2)多机位相机校准 不同相机安装过程中存在一些位置误差,或者不同车型安装相机的位置不同,这样就很难保证所有的相机的图像/特征的位置准确性,图像的上面一行表示一些偏差分布。通过MLP(Multilayer Perceptron)将每一个相机映射到虚拟相机中,由于映射到的每个虚拟相机的位置是固定的,保证了空间向量的准确性。
(3)多相机融合校准结果 后面给出了通过Transformer以及多机位的校准,可以获得准确、连续的检测结果。左图是通过多相机检测结果融合、右图是通过特征融合以及Transformer预测的结果。

下图表示的是单相机检测结果融合与多相机特征融合的检测结果比较。可见单相机检测结果融合(黄色)由于角度偏差预测的结果不准确;而多相机(蓝色)特征的融合检测结果更加准确(避免多个相机检测结果融合的不确定性)。

5、信息感知的时序性
视觉感知是缺乏时序信息的,比如表示前方的信息、信号灯、前方车辆速度等。

(1)时序/视频网络框架 提出视频模块,保留一段时序特征图,通过队列的数据结构实现(另外这里还融入了IMU信息,提升了定位、跟踪方面的准确性)。
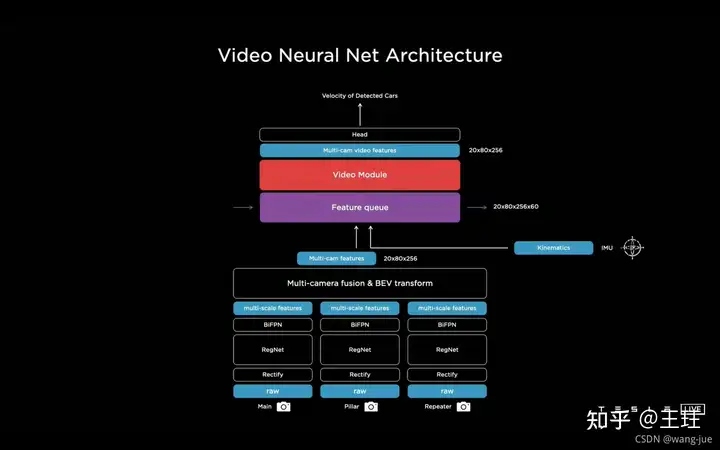
(2)特征时序序列 通过进队出队的方式维持一个时序特征图,包括多机位的特征图、位置编码、其他自身信息。基于时间或者位置进行进队操作,比如间隔27ms、行进1m等。
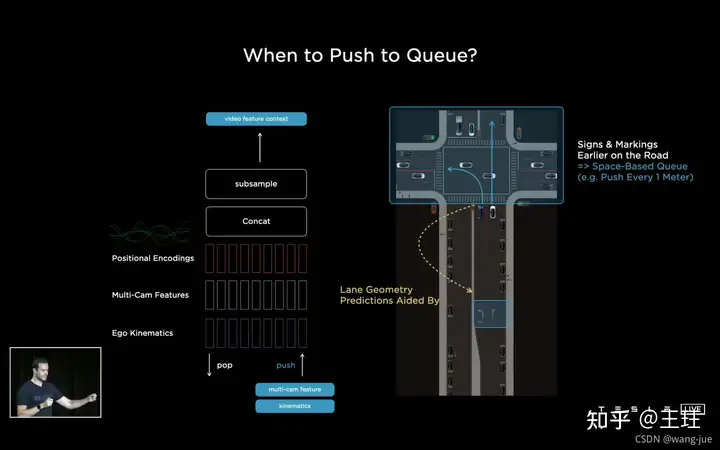
(3)Spatial RNN 现在有了时序的数据/特征,需要通过建模实现时序的特征检测,这里对比了3D Conv、Transformer、RNN三种框架,都有一定的缺点。提出Spatial RNN Video模块,车辆行驶在二维的坐标中,而Spatial RNN用来提取车辆周围一部分的特征信息实现检测(这一部分介绍的比较少,没有具体搞明白细节怎么处理的)。

(4)检测结果可视化 车辆行驶过后的检测结果可视化,可以看到很好的将驶过的路径绘制出来。由于video的时间序列,相比单帧的图像而言,可以很好的检测目标(由于帧序列的原因,对于每个目标是唯一的;而单帧图像无法确定是否为同一个目标)。

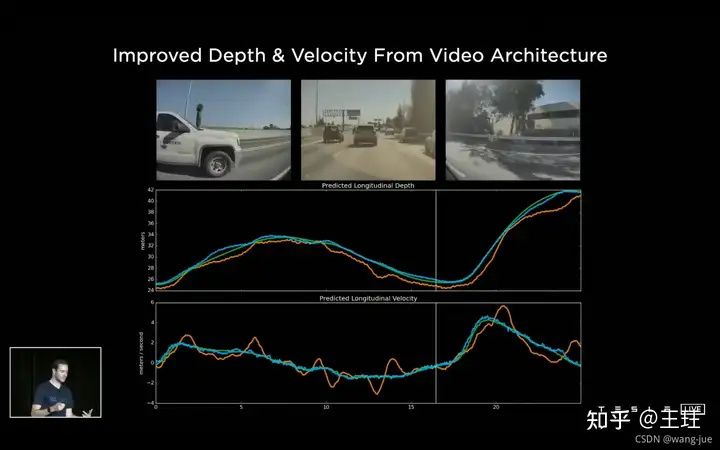
相比单帧预测的结果而言,因为时序特征序列的作用,可以很好的对前方车辆的速度进行预测(绿色是雷达计算的、蓝色是预测的结果)。
6、视觉感知框架总览
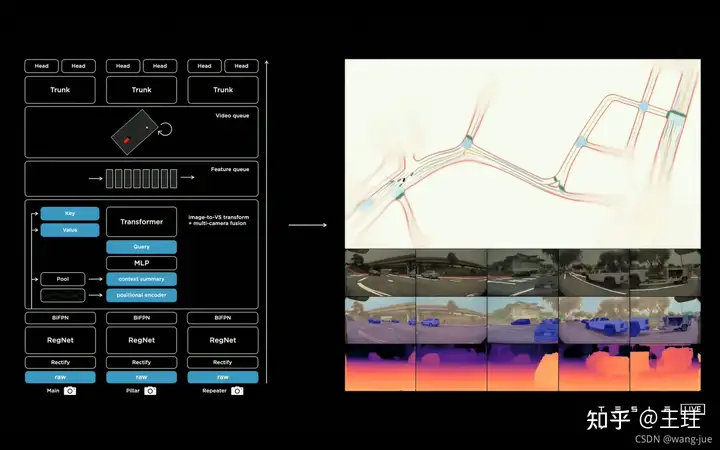
由下向上介绍: (1)多机位相机拍摄到不同角度的图像; (2)经过RegNet网络及BiFPN进行特征提取; (3)经过Transformer进行特征融合及MLP的特征修正; (4)通过队列的方式获得Video的特征; (6)经过Spatial RNN进行特征提取; (7)最终再经过不同的检测头实现车辆、行人、车道线、深度图、速度/方向等检测。
三、规划决策
升级:自动驾驶高速公路->城市、街道的开放型道路 规划决策有两个难点: (1)Non-Convex(非凸难以优化):将离散搜索转化为连续的函数优化,使用梯度下降算法会容易陷入局部最优; (2)高维的参数量(参数空间分布很广):在车辆行驶中有众多的参数,需要在接下来的几秒内做出决策,离散搜索的计算复杂度太高。 提出方法: 向量空间 -> 粗略搜索 -> 凸空间连续性 -> 连续优化 -> 平滑决策解 这里其实我不太理解,感觉是在所有的解空间中,粗略的找到一些可行的包含最优解的空间;然后在此粗略的解空间中再进行优化求解。

1、转弯问题(单个对象)
下图场景中,当前车辆在最右道,需要前进然后在路口进行左转。其中右边上图表示需要在上面一条红线之前完成转弯;下图表示车辆速度。有很多中方式: (1)先减速然后等后面的车辆驶过之后变道(缺点:突然减速,不舒适); (2)先加速超车然后变道(缺点:可能会超过转弯的距离,无法实现转弯)。
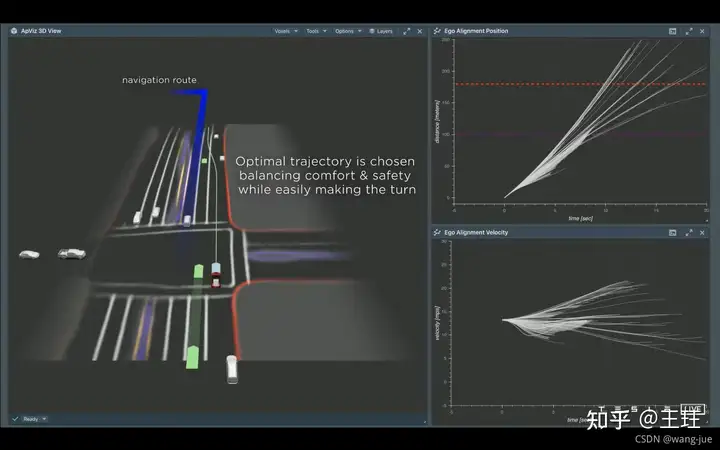
在1.5ms内搜索2500中可能方式,最终平衡舒适和安全的前提下找到一个合理的决策,然后在转弯10秒前做好转弯的规划。
2、决策问题(多对象预测--博弈)
在行驶过程中迎面而来一辆汽车,需要判断做出何种让步。这里不同于上面的单个对象,下面针对的是多个对象,因此需要考虑多对象的情况下如何进行决策。
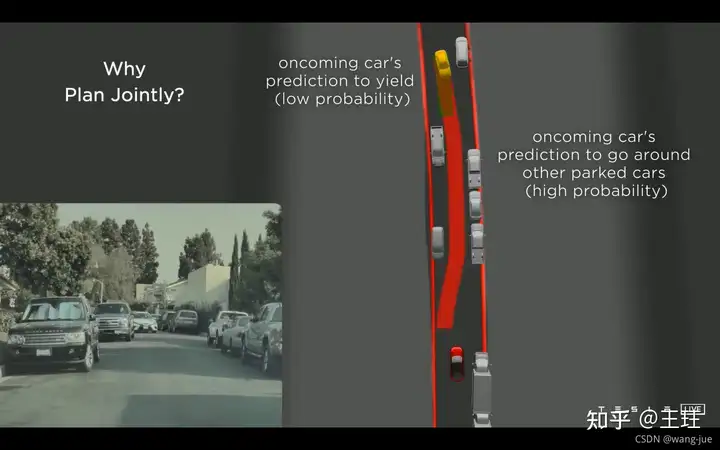
(1)如果对面速度较快,并且对方没有停车让路的空间,可能判断停下的概率较低,而不让步的概率大(于是停车,让对面先走); (2)如果对面速度较慢,或者我们行驶的较快,应该大胆的向前走,使得对面停车(避免自动驾驶的车辆过于胆小,总是让步,降低效率)。
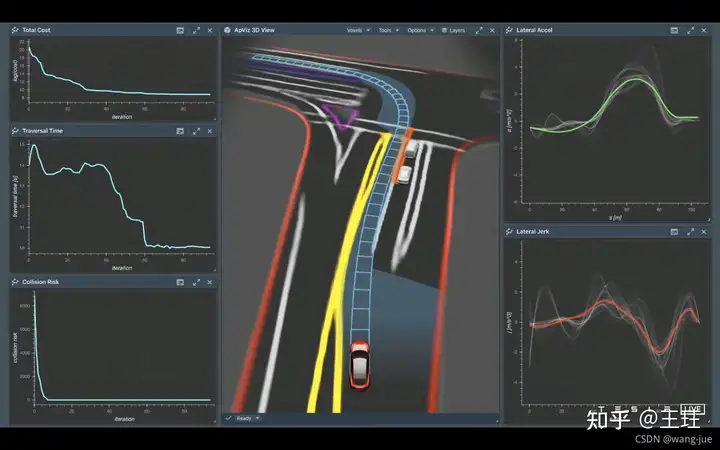
3、最优化求解
与上面两个问题相似,在转弯的过程中,已知以下内容: (1)浅色阴影部分表示可行解区域(决策空间); (2)梯状路径为当前的初始解; (3)五个图表示优化过程中的总花费、时间、风险、转弯加速度、加加速度(加加速度表示加速度快慢的量,可以理解为衡量紧急加速或者减速的情况)等。ps:这里并没有给出具体的优化求解策略。
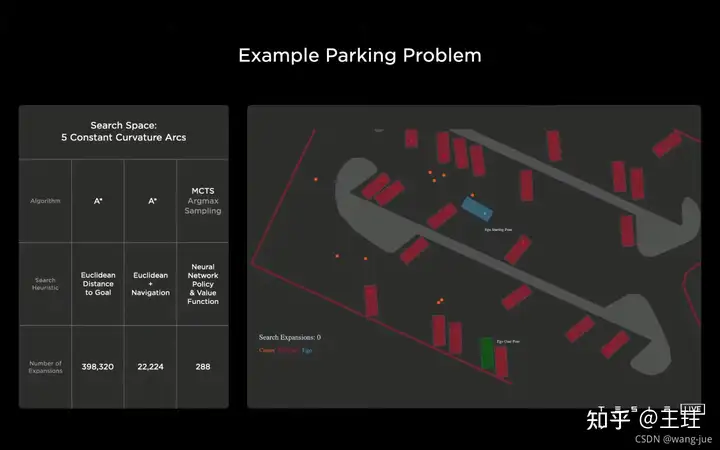
4、停车问题(基于神经网络的启发式搜索/规划)
当前车辆在蓝色格子,而车位在绿色格子,红点表示椎体。 (1)启发式搜索(A):A star算法可以理解为类似于BFS的一些算法,通过暴力搜索所有可能的路径,直到找到解为止; (2)基于导航的启发式搜索:如果知道了停车场的地图,可以按照导航的路径进行寻找,相比A提高了10倍效率(但是对于存在椎体等未知的目标时,还是会导致在局部多次搜索回退,效率极低);
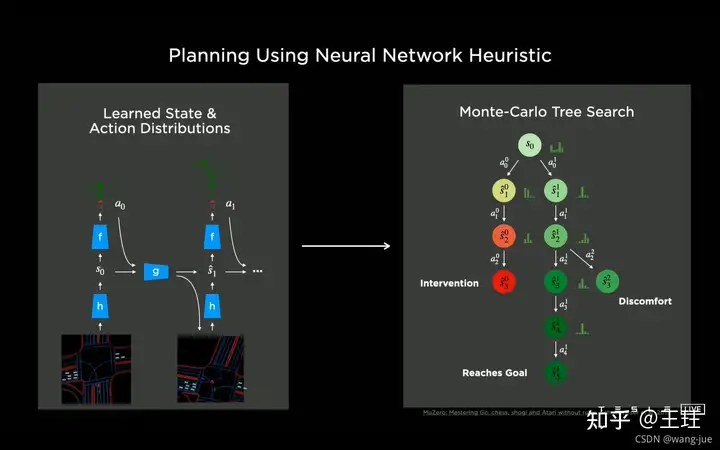
(3)基于神经网络的蒙特卡洛树搜索:通过神经网络(看图像是RNN)预测各个节点(每一步的)概率/状态,把节点放在蒙特卡洛树中进行搜索,考虑到人为介入、不舒适、不安全等因素,可以提前终止搜索。最终在此停车任务中288次搜索就完成停车求解,相比A star算法提高了千倍级别效率。
5、框架总览
整个框架分为三大块,第一部分是通过相机拍照获得视觉感知,将所有信息映射到向量空间中;第二部分是利用神经网络结合蒙特卡洛树等算法完成高效的决策求解;第三部分将求解结果输出用于控制车辆。
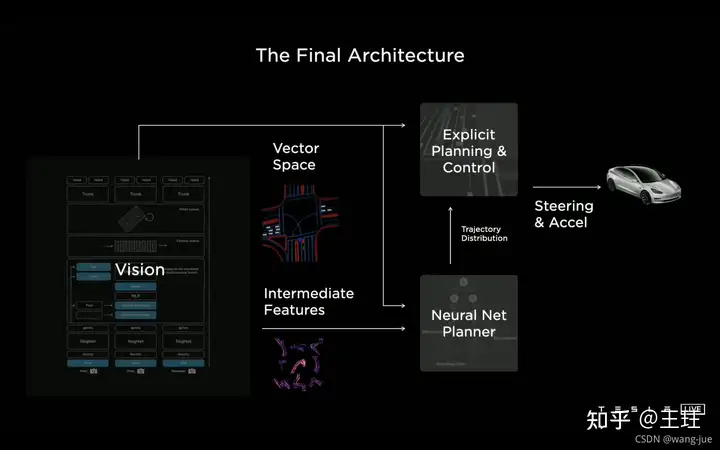
四、数据标注
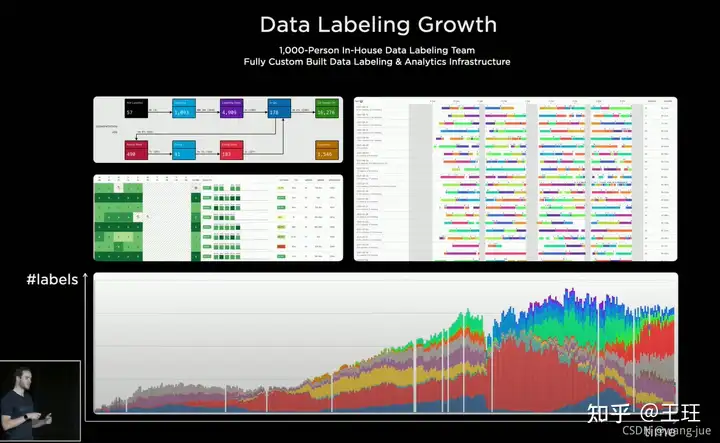
大意是说之前采用外包的数据标注,但是发现效果不是很好;后来有了一个千人左右的数据标注团队,同时进行数据结构分析(和算法团队在一起研究,才知道想要什么数据,估计这也是养了个千人的标注团队的原因吧)。
1、数据标注从2D到3D、4D
(1)采用2D进行标注时,费事费力(里面说三四年前采用2D标注); (2)现在采用3D、4D标注,直接在向量空间中进行标注(这里感觉主要是因为现在采用的算法考虑到时序深度等)。 下图是一个3D点云的重建图,在此空间中标注时,3D场景中的标签可以和2D场景中的标签相互转换;同时,3D、4D的数据可以通过目标的移动、方向的转换,获得不同角度、视野的2D图像。

2、数据自动标记
自动驾驶需要很多的标记数据,这些数据由工程车、自动驾驶车进行收集。比如下图中: (1)左边是拍摄的视频、IMU信息、GPS信息、测距等; (2)经过线下的神经网络进行预测,获得深度图、目标、坐标等; (3)经过处理,特征重建,获得重建的3D标签以及所有目标的运动趋势。

3、数据重构
图像在进行重构时,将2D图像的所有像素映射到对应的语义信息中,也就是一个2D的像素,对应一个向量空间中的像素语义。下图表示的是,车辆在路面上行驶时,通过神经网络的隐含映射,每个像素都有对应的语义信息。
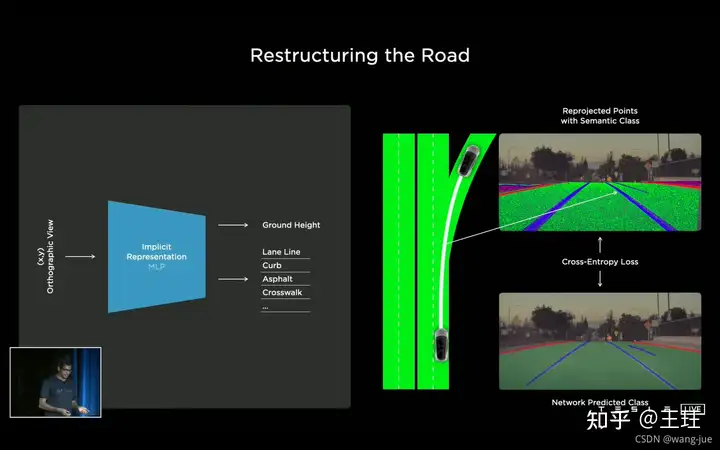
下图展现的是一个车辆在行驶时对拍摄的路面进行语义重构,可以绘制出整个道路的情况。

4、多目标/角度信息重构
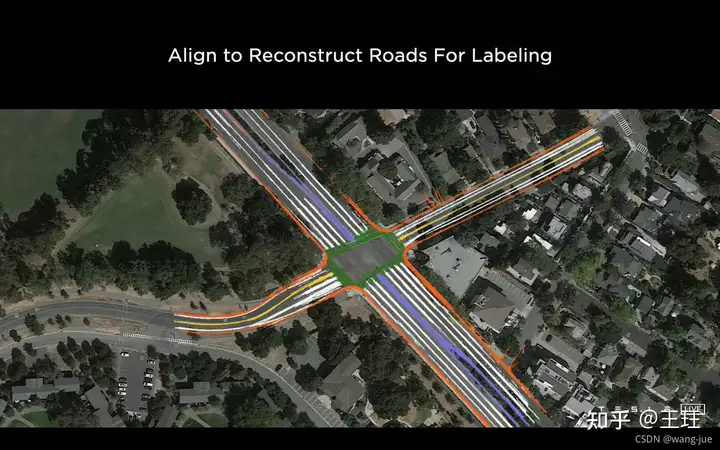
不同的车辆经过相同的位置时,拍摄到的信息不同,通过多个车辆拍摄到的结果进行融合,可以获得最新、准确的路况信息,而未经过的车辆,可以根据别的车辆走过的信息进行预判。 (1)下图展现的是多个车辆经过同一位置时绘制的不同道路语义图。

(2)多目标/车辆结果融合可以获得路况的准确信息,此外可以通过融合的方式,减少数据的误差、噪声等,提高数据的准确性。(这种技术出来可以用来重构路面信息,还可以用来重构3D点云等信息)
5、网络训练中去遮挡数据
由于拍摄的数据通过重构,可以获得3D、4D的语义信息图;在网络训练中,可以在任意时刻、任意位置获得所有目标的所有信息,在去遮挡、目标跟踪、路径、速度预测等任务中;这些高质量的数据,可以用于训练出更加强大的网络。

6、数据融合
将以上所有的技术、数据、处理过程进行融合,可以获得准确的3维信息感知。

7、基于视觉的自动驾驶(去除雷达)
通过这种数据标注的方式,在移除雷达之后,短期内效果不是很好,但是随着时间的推迟以及网络的训练加强,当存在意外情况(比如下图中车辆倾泻垃圾导致相机无法拍摄到目标)时,也能很好的预测前方车辆的速度和位置。

8、数据获取
在通过大量的车队以及投入使用的车辆,用来获取大量的极端情况下的数据,并自动标注。

五、数据仿真
1、车辆仿真
通过仿真车辆在道路上行驶,获得大量与真实场景相似的自动驾驶数据。

2、环境仿真
通过仿真,可以获得极端情况下的数据,比如下图中两个人和一个狗在高速上奔跑(左)、密集行人的运动预测(中)、复杂情况下停车(等)。

3、精确化传感器仿真
由于不同的天气、光照、角度条件下,相机/传感器获得的信息具有一定的噪声,通过对噪声的模拟增强数据的多样性,提升模型的鲁棒性。下图中左边表示的是真实情况下拍摄的结果(夜晚),右边表示仿真的结果(夜晚),考虑传感器噪声、阳光/天空光度校准、光的衍射、回复反射、运动模糊等。

4、视觉真实性传染
比如夜间拍摄时,图像存在锯齿状的伪影等,通过神经网络进行真实性渲染,降低噪声。

5、多场景、车辆、路线的仿真

6、多参数仿真
在进行仿真时,可以通过参数调整目标的数量、速度;道路的转弯角度、道路的宽窄等,用于参数无穷无尽的数据流。

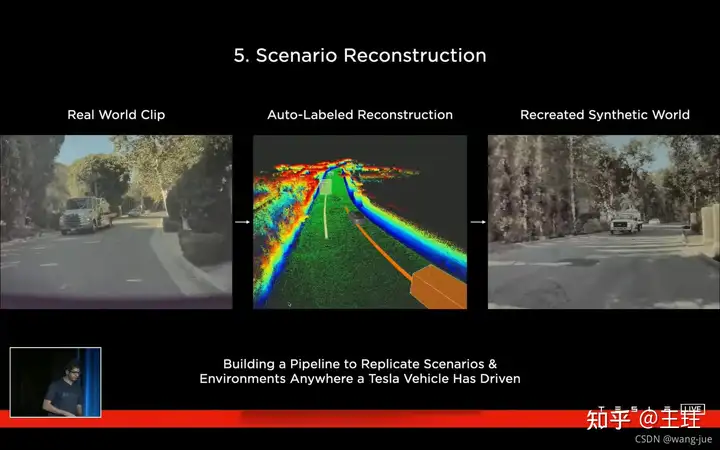
7、场景重构
下图中左边表示真实的相机拍摄结果,中间表示特征信息,右边表示场景重构的结果。通过这样的方式,当车辆遇到故障或者是复杂的情况时,通过场景重现的方式,可以重新对模型进行训练,找到错误的地方。
五、硬件
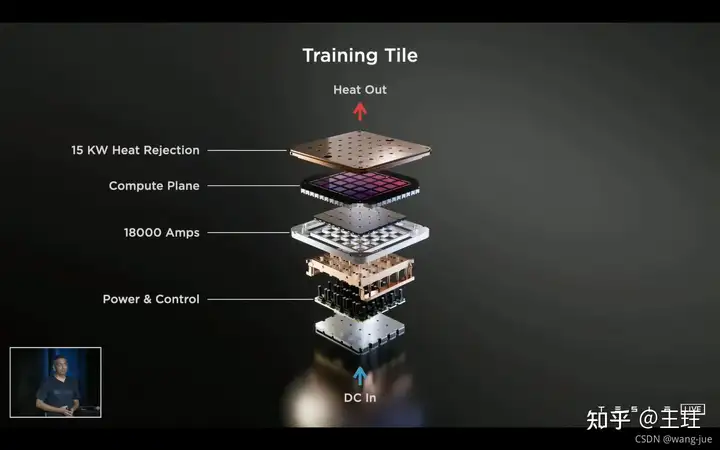
后面主要就是介绍DOJO的计算集群以及芯片方面的,由于对这些不是很懂不做解读,反而这一部分是短时间内国内最欠缺、最难超越的部分。 在算力、散热、带宽等方面都有很大的突破。这里可以移步知乎大佬的DOJO介绍。
我国人工智能、自动驾驶、GPU的发展任重而道远。
参考:
https://www.bilibili.com/video/BV1WA411c7qA?share_source=copy_web