openstack 维护注意事项
维护注意事项
1、当主机虚拟机的内存超过预设的分配内存时将导致虚拟机迁移失败。
热迁移和冷迁移都无法使用。当出现此问题时需要删除无用的虚拟机,一般此种情况常出现于物理机故障疏散且资源不足时导致。线上内存配比一般为1:1建议线上物理机准备备用机,防止物理机故障导致的情况。
2、磁盘无法读写卡死。(暂未解决),由于前面热迁移出现一些问题,重新迁移进群后看看还会不会有这个问题。
使用xfs文件系统可以解决,但xfs性能较低。
[ 1.332235] EXT4-fs (vda2): warning: mounting fs with errors, running e2fsck is recommended
[ 1.631809] EXT4-fs error (device vda2): ext4_mb_generate_buddy:757: group 240, block bitmap and bg descriptor inconsistent: 6528 vs 6516 free clusters
[ 2.430209] EXT4-fs error (device vda2): ext4_mb_generate_buddy:757: group 209, block bitmap and bg descriptor inconsistent: 1221 vs 1222 free clusters
[ 49.916783] EXT4-fs error (device vda2): ext4_mb_generate_buddy:757: group 721, block bitmap and bg descriptor inconsistent: 20823 vs 20853 free clusters
[ 92.710517] EXT4-fs error (device vda2): ext4_mb_generate_buddy:757: group 238, block bitmap and bg descriptor inconsistent: 6532 vs 6541 free clusters
[ 116.450539] EXT4-fs error (device vda2): ext4_mb_generate_buddy:757: group 673, block bitmap and bg descriptor inconsistent: 9220 vs 9327 free clusters
[ 161.499497] EXT4-fs error (device vda2): ext4_mb_generate_buddy:757: group 291, block bitmap and bg descriptor inconsistent: 18617 vs 18620 free clusters
[ 161.499951] EXT4-fs error (device vda2): ext4_mb_generate_buddy:757: group 292, block bitmap and bg descriptor inconsistent: 4458 vs 4484 free clusters
[ 161.503262] EXT4-fs error (device vda2): ext4_mb_generate_buddy:757: group 301, block bitmap and bg descriptor inconsistent: 4406 vs 4416 free clusters
[ 161.503950] EXT4-fs error (device vda2): ext4_mb_generate_buddy:757: group 302, block bitmap and bg descriptor inconsistent: 10872 vs 10931 free clusters
[ 162.196096] EXT4-fs error (device vda2): ext4_mb_generate_buddy:757: group 692, block bitmap and bg descriptor inconsistent: 5727 vs 5730 free clusters
[ 162.197240] EXT4-fs error (device vda2): ext4_mb_generate_buddy:757: group 694, block bitmap and bg descriptor inconsistent: 32527 vs 32536 free clusters
[ 302.047005] EXT4-fs (vda2): error count since last fsck: 354
[ 302.047011] EXT4-fs (vda2): initial error at time 1688137861: ext4_mb_generate_buddy:757
[ 302.047014] EXT4-fs (vda2): last error at time 1689488989: ext4_mb_generate_buddy:757
[ 3164.783725] EXT4-fs error (device vda2): ext4_mb_generate_buddy:757: group 231, block bitmap and bg descriptor inconsistent: 6400 vs 6404 free clusters
[ 4434.218499] EXT4-fs error (device vda2): ext4_mb_generate_buddy:757: group 227, block bitmap and bg descriptor inconsistent: 5728 vs 5734 free clusters
[11573.983383] EXT4-fs error (device vda2): ext4_lookup:1441: inode #5638191: comm find: deleted inode referenced: 5638210
[11573.983462] EXT4-fs error (device vda2): ext4_lookup:1441: inode #5638191: comm find: deleted inode referenced: 5638210
[11573.998703] EXT4-fs error (device vda2): ext4_lookup:1441: inode #5638191: comm find: deleted inode referenced: 5638210
[11574.005940] EXT4-fs error (device vda2): ext4_lookup:1441: inode #5638191: comm find: deleted inode referenced: 5638210
[11574.013731] EXT4-fs error (device vda2): ext4_lookup:1441: inode #5638191: comm find: deleted inode referenced: 5638210
[11574.020650] EXT4-fs error (device vda2): ext4_lookup:1441: inode #5638191: comm find: deleted inode referenced: 563821
3、OpenStack 创建虚拟机错误: Host ‘compute1‘ is not mapped to any cell
分析:前面其他错误修改后,没有重新同步发现 compute 节点
所以直接重新来过
root@controller:/home/dhbm# nova-manage cell_v2 discover_hosts --verbose
Found 2 cell mappings.
Skipping cell0 since it does not contain hosts.
Getting computes from cell 'cell1': acff5521-7a28-4a1d-bf04-6354dc5884eb
Checking host mapping for compute host 'compute2': 0186d682-fbda-4c55-a6b4-950fa35ca6e2
Creating host mapping for compute host 'compute2': 0186d682-fbda-4c55-a6b4-950fa35ca6e2
Found 1 unmapped computes in cell: acff5521-7a28-4a1d-bf04-6354dc5884eb
root@controller:/home/dhbm# openstack compute service list --service nova-compute
+----+--------------+------------+------+---------+-------+----------------------------+
| ID | Binary | Host | Zone | Status | State | Updated At |
+----+--------------+------------+------+---------+-------+----------------------------+
| 5 | nova-compute | controller | nova | enabled | up | 2022-12-06T06:26:07.000000 |
| 13 | nova-compute | compute2 | nova | enabled | up | 2022-12-06T06:26:10.000000 |
+----+--------------+------------+------+---------+-------+----------------------------+
4、只有一个网卡下的部署方案
主网卡不设置ip,通过enp1s0:0 的方式设置ip通讯,主网卡用来创建openswitch网桥,然后通讯使用浮动ip同一网段,如果没有VLAN的话。
4、接口加入自动分配的IP和网关冲突,无法设置网关
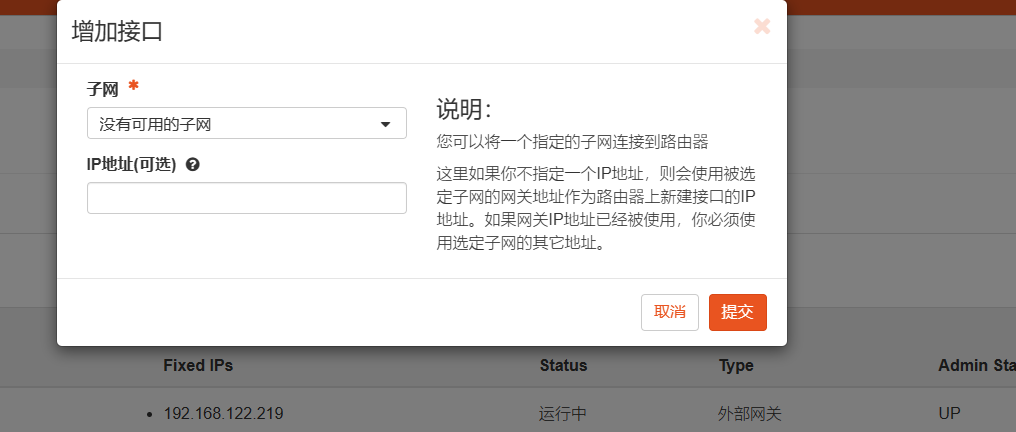
自定义一个IP
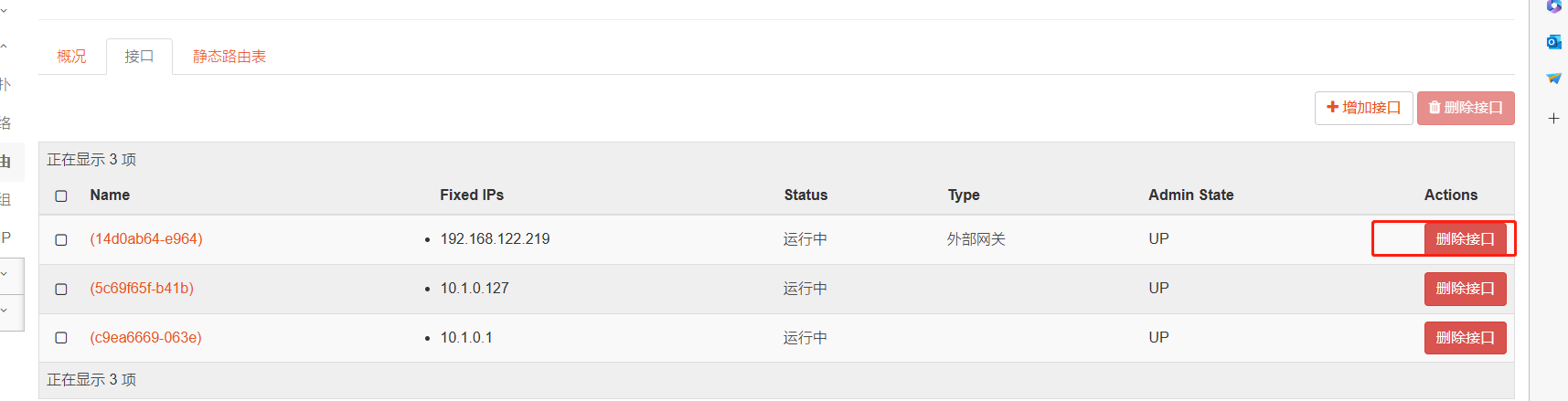
然后删除加入网络时设置的接口再设置网关即可
5、浮动ip时断时续,在内网ping发现一会是浮动ip一会是内网ip
不能在云服务器中安装ikuai等软路由,因为浮动ip是通过iptables arp组播欺骗技术做的,安装路由系统会把网卡弄成混杂模式,广播arp包和云服务器的分布式网络arp组播冲突,关闭装了路由的云服务器即可。
关闭ikuai路由后好了一段时又时不时开始出问题了,
初步怀疑是DVR网络抢断导致的,但是根据官方文档:
apt-get install --only-upgrade openvswitch-switch
systemctl restart openvswitch-switch
systemctl restart neutron-openvswitch-agent
结果问题更严重了,临时解决方案时,紧急情况下热迁移虚拟机到另一台虚拟机解决,(记得重新挂载ext4)。
暂时的根本解决方案是不用浮动IP,改用虚拟机接口直接绑定外网网卡的方案,实际测试发现安全组和热迁移都能正常使用不影响。
Centos7设置内网双网卡方案:
DHCP方案:(有缺陷,兼容问题,在创建云主机后新建的子网路由不会自动加入到之前的云主机里面去,重启网络也不行,建议使用静态IP方案)
eth0:
#mac地址记得填对或直接不填
BOOTPROTO=dhcp
DEVICE=eth0
HWADDR=fa:16:3e:20:1d:03
ONBOOT=yes
TYPE=Ethernet
USERCTL=no
eth1:
#路由优先级要比默认100低,99才能让外网网卡路由生效
TYPE=Ethernet
BOOTPROTO=static
DEFROUTE=yes
PEERDNS=yes
PEERROUTES=yes
IPV4_FAILURE_FATAL=no
NAME=eth1
DEVICE=eth1
ONBOOT=yes
IPADDR=58.215.117.240
NETMASK=255.255.255.0
GATEWAY=58.215.117.226
IPV4_ROUTE_METRIC=99
DNS1=172.16.0.232
DNS2=172.16.0.233
静态IP设置方案:
eth0:
#mac地址记得填对或直接不填,需要设置内网路由,因为这个设置不会生成内网路由,会导致内网不通。
TYPE=Ethernet
BOOTPROTO=static
DEFROUTE=yes
PEERDNS=yes
PEERROUTES=yes
IPV4_FAILURE_FATAL=no
NAME=eth0
DEVICE=eth0
ONBOOT=yes
IPADDR=10.0.32.140
NETMASK=255.255.255.0
GATEWAY=10.0.32.1
IPV4_ROUTE_METRIC=100
DNS1=172.16.0.232
DNS2=172.16.0.233
vim /etc/sysconfig/static-routes
any net 10.0.0.0/8 gw 10.0.32.1
any net 172.16.0.0/12 gw 10.0.32.1
any net 192.168.0.0/16 gw 10.0.32.1
eth1:
#路由优先级要比默认100低,99才能让外网网卡路由生效
TYPE=Ethernet
BOOTPROTO=static
DEFROUTE=yes
PEERDNS=yes
PEERROUTES=yes
IPV4_FAILURE_FATAL=no
NAME=eth1
DEVICE=eth1
ONBOOT=yes
IPADDR=58.215.117.240
NETMASK=255.255.255.0
GATEWAY=58.215.117.226
IPV4_ROUTE_METRIC=99
DNS1=172.16.0.232
DNS2=172.16.0.233
当有内网网卡其他NAT时,要先加内网自己的NAT,再做下面的绑定,下面的绑定要在NAT规则最后一条。
Chain PREROUTING (policy ACCEPT)
num target prot opt source destination
1 DNAT tcp -- anywhere anywhere tcp dpt:65306 to:10.36.0.225:3306
2 DNAT tcp -- anywhere anywhere tcp dpt:55306 to:10.101.101.44:3306
3 DNAT all -- anywhere changchun_moluo_logicserver to:10.0.32.168
Chain INPUT (policy ACCEPT)
num target prot opt source destination
Chain OUTPUT (policy ACCEPT)
num target prot opt source destination
Chain POSTROUTING (policy ACCEPT)
num target prot opt source destination
1 SNAT tcp -- anywhere 10.36.0.225 tcp dpt:mysql to:10.0.32.168
2 SNAT tcp -- anywhere 10.101.101.44 tcp dpt:mysql to:10.0.32.168
3 SNAT all -- anywhere changchun_moluo_logicserver to:58.215.117.229
当绑定两张网卡时,需要把eth0和eth1使用NAT绑定所有端口
iptables -t nat -A PREROUTING -d 58.215.117.238 -j DNAT --to-destination 10.0.32.194
iptables -t nat -A POSTROUTING -d 10.0.32.194 -j SNAT --to 58.215.117.238
iptables-save > /etc/sysconfig/iptables
添加/etc/rc.local
iptables-restore < /etc/sysconfig/iptables
6、bond带宽扩容时,引发大规模集群故障。
bond时配置的网卡数量不一致会导致数量多的一方发送数据给数量少的一方时数据发送不过去,大量丢包。引发大规模故障。网络带宽扩容时Linux 做网卡聚合时,两台服务器的网卡配置网口数量不同会导致网口数量低的服务器接收不到网卡数量高的服务器发送的通讯数据。
解决方案:
通过shell脚本,并发批量一次性快速修改网卡配置,并发同时扩容带宽,几秒钟内全部修改配置文件并扩容完成,可以避免集群大规模故障。几秒钟的中断不会对集群造成什么影响。
7、ceph自动扩容会无脑在业务高峰期扩容,且扩容时如果可用副本小于osd pool default min size,将导致集群大规模磁盘不可写,业务大规模故障,且重平衡和扩容时间极其长达两三个小时。
解决方案:
查看详情:
ceph osd pool ls detail
关闭自动扩容:
ceph osd pool set <pool-name> pg_autoscale_mode off
关闭自动重平衡:
ceph balancer off 设
置最小和最大pgm 防止误操作导致扩容
ceph osd pool set <pool-name> pg_num_max <num>
ceph osd pool set <pool-name> pg_num_min <num>
在业务低谷期一个一个pgm增加扩容
#/bin/bash
mubiaopgs=$1
xianyoupgs=`ceph osd pool ls detail | grep volumes | awk -F"pgp_num" '{print $2}' | awk -F" " '{print $1}'`
check_cephstatus(){
ceph_s=`ceph -s | grep active | grep -v pgs | grep -v mgr | wc -l`
ceph_dump_s=`ceph pg dump_stuck | wc -l`
echo $ceph_s
echo $ceph_dump_s
result=0
if [ $ceph_s -ne 0 ];then
result=1
fi
if [ $ceph_dump_s -ne 0 ];then
result=2
fi
}
while [ $xianyoupgs -lt $mubiaopgs ]
do
osdisdown=`ceph osd tree | grep down | wc -l`
if [ $osdisdown -ne 0 ];then
echo "发现 osd down,停止扩容"
date>>osd_status.log
ceph osd tree>>osd_status.log
echo>>osd_status.log
echo>>osd_status.log
echo>>osd_status.log
exit
fi
check_cephstatus
if [ $result -eq 0 ];then
xianyoupgs=`expr $xianyoupgs + 1`
date
ceph osd pool set volumes pg_num $xianyoupgs
# ceph_s=`ceph -s | grep active | grep -v pgs | grep -v mgr | wc -l`
# while [ $ceph_s -eq 0 ]
# do
# echo "等待扩容中"
# echo $ceph_s
# sleep 15
# ceph_s=`ceph -s | grep active | grep -v pgs | grep -v mgr | wc -l`
# done
fi
sleep 25
done
8、Linux镜像jbd2进程长时间卡磁盘100%占满IO,目前Cetons7和Ubuntu的EXT4文件系统中皆有发现。
兴动云上的Centos系统官方镜像存在一个EXT4日志文件系统的bug,int整型溢出会导致系统中的一个核心CPU IOWAIT 长时间100%占满,目前测试已通过升级系统内核,和修改文件系统挂载参数关闭日志功能解决,测试云服务器中测试通过。
解决方案:
Centos7:
yum update kernel
findmnt (确认磁盘类型为ordered)
vim /etc/fstab
defaults,rw,noatime,nodiratime,barrier=0,data=ordered,commit=60
mount -a
reboot
findmnt
不停机方案:
findmnt (确认磁盘类型为ordered)
vim /etc/fstab
defaults,rw,noatime,nodiratime,barrier=0,data=ordered,commit=60
mount -a
mount -o remount,noatime,nodiratime,barrier=0,data=ordered,commit=60 /
mount -o remount,noatime,nodiratime,barrier=0,data=ordered,commit=60 /boot
findmnt
Ubuntu20.04:
findmnt (确认磁盘类型为ordered)
vim /etc/fstab
defaults,rw,noatime,nodiratime,barrier=0,data=ordered,commit=60
mount -a
reboot
findmnt
不停机方案:
findmnt (确认磁盘类型为ordered)
vim /etc/fstab
defaults,rw,noatime,nodiratime,barrier=0,data=ordered,commit=60
mount -a
mount -o remount,noatime,nodiratime,barrier=0,data=ordered,commit=60 /
mount -o remount,noatime,nodiratime,barrier=0,data=ordered,commit=60 /boot
Findmnt
9、创建虚拟机时,提示No valid host was found解决办法
一般是计算节点资源不足无法创建导致ide
10、磁盘维护:
查看磁盘寿命信息和温度:
smartctl -a /dev/nvme01
ceph写入时延高导致虚拟机hang死的故障处理
查看硬盘时延:
ceph osd perf
调整osd reweight,让pg不再分配读写到这个osd
ceph osd reweight 64 0
11、osd占用内存过高:
ceph运维大宝剑之osd内存调查 | 奋斗的松鼠 - blog (strugglesquirrel.com)
所有ceph.conf 文件添加配置,限制内存为1T=1G,2T=2G,以此类推。
[osd]
osd_memory_target = 1073741824
# 查看整个集群的配置ceph-conf --show-config
# 查看特定OSD的配置
ceph config show osd.0
ceph daemon osd.0 config show
ceph 查看默认配置、内存、延迟等相关维护操作 | 辣条部落格 (wsfnk.com)
ceph daemon osd.0 config show
ceph 查看默认配置、内存、延迟等相关维护操作 | 辣条部落格 (wsfnk.com)
11、ceph升级方法:
注意
- 将mon节点从Luminous升级到Nautilus后,Luminous 将无法创建新的osd进程.不要在升级过程中添加或替换任何OSD。
- 不要在升级过程中创建存储池。
备份旧版本数据
官方没有相关说明,为了保险所有操作都进行备份,官方建议升级之前做过完整的scrub
cp -r /var/lib/ceph/ /var/lib/ceph-l/
准备升级源
root@demo:/home/demouser# vi /etc/apt/sources.list.d/ceph.list
deb http://mirrors.yyuap.com/ceph/debian-nautilus xenial main #使用内部源
root@demo:/home/demouser# apt-get update
...
Fetched 18.7 kB in 11s (1,587 B/s)
Reading package lists... Done
执行升级
ceph osd set noout
apt install ceph
确认升级
重启mon
systemctl restart ceph-mon@$(hostname -s)
查看mon版本
ceph mon dump | grep min_mon_release
查看osd版本
ceph osd versions
查看所有版本
ceph versions
参考文档:https://docs.ceph.com/en/nautilus/releases/nautilus/#upgrading-from-mimic-or-luminous
12、openstack 上 ceph 存储数据库性能极差问题:
安装数据库:
systemctl stop iptables
systemctl stop firewalld
systemctl disable iptables
systemctl disable firewalld
#选择一:安装mysql5.7
sudo yum install -y wget
wget https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm
#Mysql8.0
wget https://repo.mysql.com//mysql80-community-release-el7-10.noarch.rpm
sudo yum localinstall mysql80-community-release-el7-3.noarch.rpm -y
sudo yum install -y yum-utils
yum repolist enabled | grep "mysql.*-community.*"
yum repolist all | grep mysql
sudo yum-config-manager --disable mysql80-community
sudo yum-config-manager --enable mysql57-community
yum repolist enabled | grep mysql
rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022
sudo yum install -y mysql-community-server
#选择二:安装mysql8.0
sudo yum install -y wget
wget https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm
sudo yum localinstall mysql80-community-release-el7-3.noarch.rpm -y
sudo yum install -y yum-utils
yum repolist enabled | grep "mysql.*-community.*"
yum repolist all | grep mysql
sudo yum-config-manager --enable mysql80-community
yum repolist enabled | grep mysql
rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022
sudo yum install -y mysql-community-server
修改mysql配置文件,两个关键项:
sync_binlog=0
innodb_flush_log_at_trx_commit=2
这两个选项是交给系统写入磁盘,防止MYSQL直接写磁盘,然后通过MYSQL半同步主从,防止单点数据库宕机导致数据丢失。注意主从数据库不能在一台宿主机上。
innodb_buffer_pool_size = 8134M #设置为主机内存的50%,防止持续高压力导致的MYSQL被kill掉重启。
主数据库:
vim /etc/my.cnf
# For advice on how to change settings please see
# http://dev.mysql.com/doc/refman/5.7/en/server-configuration-defaults.html
[mysqld]
#
# Remove leading # and set to the amount of RAM for the most important data
# cache in MySQL. Start at 70% of total RAM for dedicated server, else 10%.
innodb_buffer_pool_size = 8134M
#
# Remove leading # to turn on a very important data integrity option: logging
# changes to the binary log between backups.
# log_bin
#
# Remove leading # to set options mainly useful for reporting servers.
# The server defaults are faster for transactions and fast SELECTs.
# Adjust sizes as needed, experiment to find the optimal values.
# join_buffer_size = 128M
# sort_buffer_size = 2M
# read_rnd_buffer_size = 2M
bulk_insert_buffer_size = 512M
innodb_log_file_size = 512M
key_buffer_size = 1600M
back_log = 350
datadir=/data/app/mysql/mysqldata
log-error=/var/log/mysqld.log
default-storage-engine=INNODB
character-set-server=utf8
collation-server=utf8_general_ci
sql_mode=STRICT_TRANS_TABLES,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION
max_allowed_packet=1024M
innodb_buffer_pool_chunk_size = 1G
innodb_buffer_pool_instances = 8
skip-name-resolve
lower_case_table_names = 1
max_connections=1024
server-id=1
log-bin=mysql-bin
binlog-format=ROW
sync_binlog=0
innodb_flush_log_at_trx_commit=2
slow_query_log = ON
long_query_time = 1
max_binlog_size=1000M
expire_logs_days=7
plugin-load="rpl_semi_sync_master=semisync_master.so;rpl_semi_sync_slave=semisync_slave.so"
rpl_semi_sync_master_enabled=1
rpl_semi_sync_slave_enabled=1
rpl_semi_sync_master_wait_no_slave=ON #如果主库和所有从库都无法正常连接,是否还继续等待从库的ACK信息,默认为ON
rpl_semi_sync_master_wait_for_slave_count=1 #需要至少多少个从库完成确认
rpl_semi_sync_master_wait_point=AFTER_SYNC #AFTER_COMMIT性能最差,且不能无损,所以不推荐
rpl_semi_sync_master_timeout=500 #半同步超时时间,超时后转为异步复制,单位为毫秒
socket=/var/lib/mysql/mysql.sock
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
log-error=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
[client]
user='root'
password='Mysql@rootpassword123'
default-character-set=utf8
从数据库:
vim /etc/my.cnf
# For advice on how to change settings please see
# http://dev.mysql.com/doc/refman/5.7/en/server-configuration-defaults.html
[mysqld]
#
# Remove leading # and set to the amount of RAM for the most important data
# cache in MySQL. Start at 70% of total RAM for dedicated server, else 10%.
innodb_buffer_pool_size = 8134M
#
# Remove leading # to turn on a very important data integrity option: logging
# changes to the binary log between backups.
# log_bin
#
# Remove leading # to set options mainly useful for reporting servers.
# The server defaults are faster for transactions and fast SELECTs.
# Adjust sizes as needed, experiment to find the optimal values.
# join_buffer_size = 128M
# sort_buffer_size = 2M
# read_rnd_buffer_size = 2M
bulk_insert_buffer_size = 512M
innodb_log_file_size = 512M
key_buffer_size = 1600M
back_log = 350
datadir=/data/app/mysql/mysqldata
log-error=/var/log/mysqld.log
default-storage-engine=INNODB
character-set-server=utf8
collation-server=utf8_general_ci
sql_mode=STRICT_TRANS_TABLES,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION
max_allowed_packet=1024M
innodb_buffer_pool_chunk_size = 1G
innodb_buffer_pool_instances = 8
skip-name-resolve
lower_case_table_names = 1
max_connections=1024
read_only=ON
server-id=2
log-bin=mysql-bin
binlog-format=ROW
sync_binlog=0
innodb_flush_log_at_trx_commit=2
slow_query_log = ON
long_query_time = 1
plugin-load="rpl_semi_sync_master=semisync_master.so;rpl_semi_sync_slave=semisync_slave.so"
rpl_semi_sync_master_enabled=1
rpl_semi_sync_slave_enabled=1
rpl_semi_sync_master_wait_no_slave=ON #如果主库和所有从库都无法正常连接,是否还继续等待从库的ACK信息,默认为ON
rpl_semi_sync_master_wait_for_slave_count=1 #需要至少多少个从库完成确认
rpl_semi_sync_master_wait_point=AFTER_SYNC #AFTER_COMMIT性能最差,且不能无损,所以不推荐
rpl_semi_sync_master_timeout=500 #半同步超时时间,超时后转为异步复制,单位为毫秒
socket=/var/lib/mysql/mysql.sock
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
log-error=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
[client]
user='root'
password='Mysql@rootpassword123'
default-character-set=utf8
输入命令,启动mysql:
mkdir -p /data/app/mysql/mysqldata
chown -R mysql.mysql /data/app/mysql
systemctl disable mysqld
systemctl enable mysqld
mysqld --initialize --console --user mysql
cat /var/log/mysqld.log
systemctl start mysqld
mysql -uroot -p
#输入cat /var/log/mysqld.log显示的密码
mysql启动完成后,输入命令修改root账号密码:
alter user user() identified by "XingdongMysql@rootpassword123888";
flush privileges;
update mysql.user set host='%' where user='root';
flush privileges;
#mysql8.0额外执行:
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY 'xxxxxx';
#建用户语句
#5.7:
grant all privileges on *.* to 'xd_tl_admin'@'%' identified by "xxxxxx";
flush privileges;
#8.0:
grant system_user on *.* to 'root';
create user 'xgame'@'%' identified by 'xxxxxx';
grant all privileges on *.* to 'xgame'@'%';
ALTER USER 'xgame'@'%' IDENTIFIED WITH mysql_native_password BY 'xxxxxx';
flush privileges;
数据库主从配置:
①、首先在数据库主库执行数据导出命令将数据库导出到databases.sql文件中,导出后查看文件中携带的主库LOG信息
#主库执行导出数据及查看,注意root用户名密码
mysqldump -uroot -pxxxxxx --single-transaction --master-data=2 --all-databases> databases.sql
head -n 30 databases.sql
②、将databases.sql文件传输至数据库从库,完成后执行命令开启从库slave模式
#从库执行,注意root用户名密码
mysql -uroot -pxxxxxx
source databases.sql;
#从库设置LOG参数,其中master_host为从库访问主库的ip地址,master_log_file和master_log_pos就是第1步查看的LOG信息
change master to master_host='10.0.32.161',master_user='root',master_port=3306,master_password='xxxxxx',master_log_file='mysql-bin.000003',master_log_pos=521780865;
start slave;
binlog导致磁盘满的情况,只需要删除主库的所有binlog然后重启主库即可。然后看从库如果主从断了,就 start slave 一下。
13、虚拟机实例大小调整。
项目-》实例-》调整实例大小即可。(会重启服务器)
如果调整失败则查看 nova-compute日志,调整实例惠自动迁移,需要在nova用户下做目标主机的免密登录。(只能调整内存和CPU,无法调整硬盘)
14、虚拟机扩容硬盘(重启服务器)。
项目-》实例—》点击进入虚拟机名称—》点击连接的卷——》扩展卷
如果扩容失败就改代码:
先得知道扩容的磁盘管理在哪台物理机上:
openstack volume show da1e1342-155d-4ce7-adfd-267dd274bf80
找到字段:
os-vol-host-attr:host
例如:
compute04@ceph#ceph
则登录物理机compute04
修改代码:
vim /usr/lib/python3/dist-packages/cinder/compute/nova.py
第106行:
LOG.debug('Creating Keystone token plugin using URL: %s', url)
下面添加:
context.project_domain_id='default'
重启cinder服务:
systemctl restart cinder-volume
重新扩容即可。
shutdown 关闭虚拟机。
关闭成功点击硬重启
启动后
fdisk /dev/vda
查看硬盘大小是否扩充成功。
然后扩容分区:
1.查看现有分区
df -h
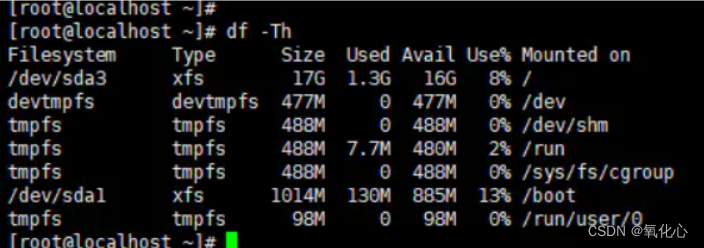
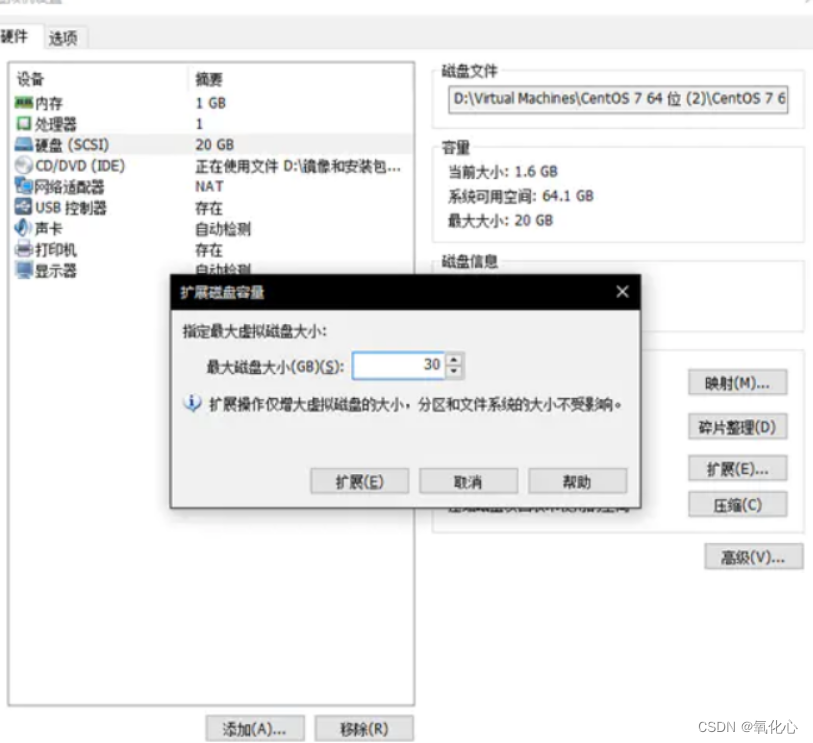
2.关机增加磁盘大小
3.查看磁盘扩容后状态
lsblk
dh -h

4.进行分区扩展磁盘,记住根分区起始位置和结束位置。
4.1选则要操作的磁盘
fdisk /dev/sda
4.2查看已分区数量
p
4.3删除根分区文章来源地址https://www.yii666.com/blog/381507.html网址:yii666.com<
# 删除
d
#挂载根目录sda3
3
# 查看磁盘分配
p
4.4创建分区
# 新增分区
n
# 查看磁盘分配
p
#创建的是sda3
3
# 把剩余空间都分配
起始位置大小 回车
结束位置大小 回车
# 查看分区
p
# 保存同步
w
4.5 保存退出并刷新分区文章来源地址:https://www.yii666.com/blog/381507.html
partpeobe /dev/sda
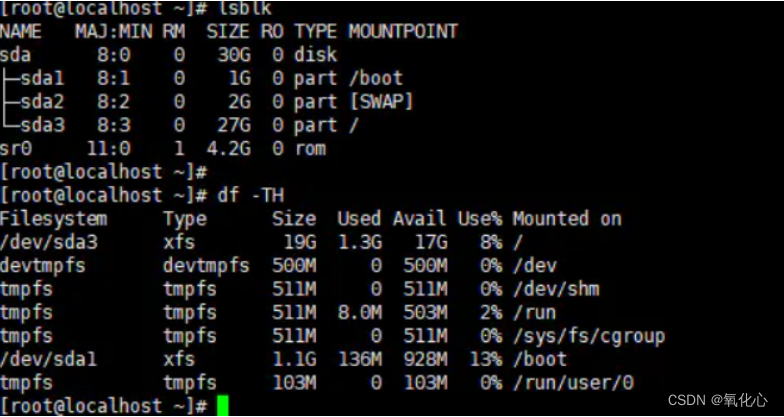
5 查看分区状态
lsblk
df -TH
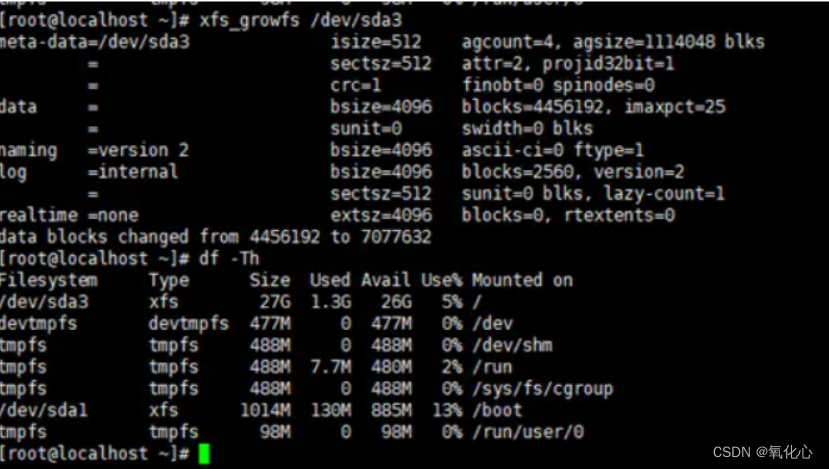
6 扩展磁盘空间,并查看状态
# 首先确认下磁盘格式是xfs,还是ext4
# 磁盘格式是xfs,
xfs_growfs /dev/sda3
# 磁盘格式 ext4
resize2fs /dev/sda3
df -TH
14、热迁移后虚拟机IO性能急速下降。
问题原因:openstack和barrier兼容问题。热迁移后重新开关下barrier挂载参数即可。
登录热迁移后的云服务器:
开一下barrier:
mount -o remount,noatime,nodiratime,barrier=1,data=ordered,commit=60 /
mount -o remount,noatime,nodiratime,barrier=1,data=ordered,commit=60 /boot
关一下barrier:
mount -o remount,noatime,nodiratime,barrier=0,data=ordered,commit=60 /
mount -o remount,noatime,nodiratime,barrier=0,data=ordered,commit=60 /boot
开业考虑使用命令发送的方式通过openstack 直接发送命令到云主机,只重新mount 关barrier 也行。
15、云主机突然自己强制关机。
由于openstack 会自动比对数据库和kvm 的启动状态,不一致时会强制关机云主机。只需要在nova.conf配置文件添加如下配置:
关闭同步电源设置和关闭清理镜像配置。
[default]
sync_power_state_interval=-1
image_cache_manager_interval=-1
16、虚拟化宿主机物理机监控显示带宽爆满,影响业务。
nohup iftop -NP -i bond0 -n -b -o 2s -t -L 10 >iftop.log &
监测网卡找到打满带宽的IP和端口。
iftop 网卡实时流量监测
通过命令cat iftop.log | grep Gb | grep "=>"
查找
17、磁盘限速带宽,防止打崩物理机。
openstack kvm 磁盘限速 – 静安的博客 (7890.ink)
18、bond0导致网卡性能变低。
更换为bond4 802ad
# This is the network config written by 'subiquity'
network:
ethernets:
eno1:
dhcp4: true
enp11s0f0:
dhcp4: false
enp11s0f1:
dhcp4: false
enp11s0f2:
dhcp4: false
enp11s0f3:
dhcp4: true
version: 2
bonds:
bond0:
interfaces:
- enp11s0f0
- enp11s0f1
- enp11s0f2
macaddress: "a6:a4:11:a0:2b:00"
parameters:
mode: 802.3ad
mii-monitor-interval: 100
lacp-rate: fast
transmit-hash-policy: layer3+4
vlans:
vlan11:
id: 11
link: bond0
addresses: [ "11.0.0.2/24" ]
routes:
- to: default
via: 11.0.0.1
19、浮动ip丢包
可能为备份控制节点和控制节点同时启动了网络路由导致跳来跳去,而且这个问题还会导致整个集群大规模崩溃。升级了网卡为bond4以及关闭备份节点的所有软件并重启,特别是ipn netns为空后,好像好了。
systemctl disable mariadb rabbitmq-server memcached etcd keystone glance-api placement-api apache2 nova-api nova-conductor nova-novncproxy nova-scheduler neutron-server neutron-plugin-ml2 openvswitch-switch neutron-openvswitch-agent neutron-l3-agent neutron-dhcp-agent neutron-metadata-agent neutron-dhcp-agent.service neutron-l3-agent.service neutron-metadata-agent.service neutron-openvswitch-agent.service neutron-server.service nova-api cinder-scheduler nova-compute
关闭后还有发现一个包这种情况。继续观察。
20、Ceph 查看所有卷 iops
问题场景
使用方法
处理方案
-
通过卷找出对应云硬盘,对其进行 qos 限制。
-
将对 iops 要求高的卷迁移至性能更高的存储池,比如 ssd 存储池
注意事项
21、OPENSTACK上传镜像到GLANCE和修改镜像密码:
openstack上传镜像到glance – 静安的博客 (7890.ink)
22、虚拟机热迁移失败
在目的物理机修改[service_user]配置
[service_user]
send_service_user_token = true
auth_url = http://controller01:5000/v3
auth_type = password
project_domain_name = Default
project_name = service
user_domain_name = Default
username = nova
password = nova
23、如何制作windows镜像:
1、首先下载windows ISO 镜像和virtio驱动: https://fedorapeople.org/groups/virt/virtio-win/direct-downloads/archive-virtio/virtio-win-0.1.240-1/virtio-win-0.1.240.iso
2、然后用 virt-manager 安装ISO系统,新建虚拟机时把磁盘和网卡类型都改为 virtio 类型。新建的时候主机操作系统记得选对,不然导入驱动好像会有问题。
3、把驱动的ISO也当CDROM挂载到虚拟机上去。
4、开始安装系统,安装时识别不到硬盘,我们把 virtio 中的驱动一个一个手动导入进去安装。
5、识别到硬盘并安装成功后,设置好密码,远程桌面,激活等重启一次再关机。
6、压缩QCOW2文件:qemu-img convert -c -O qcow2 win2k22.qcow2 win2k22_y.qcow2
7、上传镜像到openstack是使用:glance image-create --name win2022_y --disk-format qcow2 --container bare --file win2k22_y.qcow2
24、openstack ip带宽流量限制:
服务质量 (QoS) — Neutron 21.2.1.dev40 文档 (openstack.org)
25、ceph 查看所有卷实际占用空间:
rbd du -p volumes
26、新建用户初始化默认值为0
openstack quota set --cores 0 --ram 0 --instances 0 --gigabytes 0 --volumes 0 --key-pairs 0 --server-groups 0 --snapshots 0 --backups 0 --routers 0 --networks 0 aaa
--cores 设置CPU核心数
--ram 设置内存例如1G内存为1024
--instances 设置实例数量
--gigabytes 设置磁盘空间限制例如10代码10G
--volumes 设置磁盘数量
--key-pairs 设置密钥数量
--server-groups 设置云主机组数量
--snapshots 设置快照数量
--backups 设置云硬盘备份数量
--routers 设置路由器数量
--networks 设置网络数量
aaa 选择需要设置的项目名
27、ceph数据重建影响业务处理:
ceph数据recovery配置策略(数据recovery流量控制) – 静安的博客 (7890.ink)
调整脚本,例如故障的物理机和磁盘为9,10,11,12
#!/bin/bash
for item in {0..47}
do
if (( item < 9 || item > 12 )); then
# 执行循环体内的命令
echo $item
ceph tell osd.$item injectargs '--osd-max-backfills 1 --osd-recovery-max-active 1 --osd-recovery-max-single-start 1 --osd_recovery_op_priority 1'
ceph tell osd.$item injectargs '--osd-recovery-sleep 1'
fi
done
查看调整是否生效
ceph --admin-daemon /var/run/ceph/ceph-osd.0.asok config show | grep -E "osd_max_backfills|osd_recovery_max_active|osd_recovery_max_single_start|osd_recovery_op_priority"
"osd_max_backfills": "1",
"osd_recovery_max_active": "1",
"osd_recovery_max_active_hdd": "10",
"osd_recovery_max_active_ssd": "20",
"osd_recovery_max_single_start": "1",
"osd_recovery_op_priority": "1",
4个代表没问题
当然,如果恢复太慢也能加快
ceph recovering速度控制-腾讯云开发者社区-腾讯云 (tencent.com)
ceph配置文件说明:
[global]
fsid = ee733486-561a-4781-9973-1f6b38329141
mon initial members = controller01
mon host = 11.0.0.2
public network = 11.0.0.0/24
cluster network = 11.0.0.0/24
auth cluster required = cephx
auth service required = cephx
auth client required = cephx
osd journal size = 1024
osd pool default size = 2
osd pool default min size = 1
osd pool default pg num = 64
osd pool default pgp num = 64
osd crush chooseleaf type = 1
max open files = 1024000
[osd]
osd_max_backfills=256 #设置 OSD 同时进行的最大后台恢复任务数
osd_recovery_op_priority=2 #设置 OSD 恢复操作的优先级,值越大优先级越高,最大63
osd_recovery_max_active=128 #设置系统同时进行的 OSD 恢复操作的最大数量
osd_recovery_max_single_start=128 #设置每个 OSD 同时启动的最大恢复操作数
osd_recovery_sleep_hdd=0 #控制在 OSD HDD类型 恢复操作之间休眠的时间,0 表示不休眠。
osd_recovery_sleep_ssd=0 #控制在 OSD SSD类型 恢复操作之间休眠的时间,0 表示不休眠。
osd_recovery_max_active_hdd=128 #针对 HDD设置同时进行的最大恢复操作数量
osd_recovery_max_active_ssd=128 #针对 SSD设置同时进行的最大恢复操作数量
osd_min_recovery_priority=1 #OSD 最小恢复优先级
osd_recovery_priority=2 #为恢复工作队列设置的默认优先级
临时调整:
ceph tell osd.* injectargs --osd_max_backfills=256
ceph tell osd.* injectargs --osd_recovery_max_active=128
ceph tell osd.* injectargs --osd_recovery_sleep_hdd=0
ceph tell osd.* injectargs --osd_recovery_sleep_ssd=0
ceph tell osd.* injectargs --osd_recovery_max_active_hdd=128
ceph tell osd.* injectargs --osd_recovery_max_active_ssd=128
ceph tell osd.* injectargs --osd_min_recovery_priority=1
注意:
osd_recovery_priority
osd_recovery_op_priority
osd_recovery_max_single_start
只能修改配置文件调整。
27、手动修改Ceph识别错误的磁盘类型|HDD改成SSD
ceph osd out 43
ceph osd crush rm-device-class 43
ceph osd crush set-device-class ssd 43
ceph osd reweight 43 0.8
28、彻底删除OSD
ceph osd out 43
ceph osd crush rm-device-class 43
ceph osd crush remove osd.43
ceph osd rm osd.43ceph auth del osd.43
29、使用集群中唯一一个MON恢复集群ceph-mon服务(记一次故障恢复)
systemctl stop ceph-mon.target
systemctl stop ceph-mgr.target
systemctl stop ceph-osd@1
停掉所有的ceph进程
ceph-mon -i $(hostname -s) --extract-monmap /tmp/lastmap
# 手动移除异常mon
monmaptool /tmp/lasmap --rm mon1(异常mon的主机名)
monmaptool /tmp/lasmap --rm mon2(异常mon的主机名)
ceph-mon -i mon0 --inject-monmap /tmp/lastmap
重启服务器
使用集群中唯一一个MON恢复集群ceph-mon服务(记一次故障恢复)_ceph只保留一个mon-CSDN博客