Cep PG 和 OSD 状态分析状态表和不可用状态注意
前言
但凡pg状态没有处于active,那么io都会阻塞的
作为一个成熟、可靠的分布式存储框架,Ceph集群中的各个组件都具备很强的自运维能力,这样的能力都是依托于 Ceph 优秀的故障检测机制。这篇文章主要分析一下集群状态的变迁。
Ceph OSD 状态分析
up、down代表OSD临时故障或下电,不会发起数据恢复;in、out代表被踢出集群,集群发起数据恢复。OSD 的状态通过心跳检测的方式被集群确认,即拥有心跳的 OSD 被标记为 up,心跳停止的 OSD 则被标记为 down。当 OSD 被标记为 down的时间超过的阈值(默认为600秒)时,OSD 被标记为 out。
| 状态 | 描述 |
|---|---|
| in | OSD在Ceph集群内 |
| out | OSD在Ceph集群外 |
| up | OSD(心跳)活着且在运行 |
| down | OSD 挂了且不再运行 |
Ceph OSD 心跳检测
心跳是用于节点间检测对方是否故障的,以便及时发现故障节点进入相应的故障处理流程。作为分布式集群,集群在设计心跳策略时,需要考虑的问题包括:
a. 故障检测时间和心跳报文带来的负载之间做权衡。
b. 心跳频率太高则过多的心跳报文会影响系统性能。
c. 心跳频率过低则会延长发现故障节点的时间,从而影响系统的可用性。
故障检测策略应该能够做到:
a. 及时:节点发生异常如宕机或网络中断时,集群可以在可接受的时间范围内感知。
b. 适当的压力:包括对节点的压力,和对网络的压力。
c. 容忍网络抖动:网络偶尔延迟。
d. 扩散机制:节点存活状态改变导致的元信息变化需要通过某种机制扩散到整个集群。
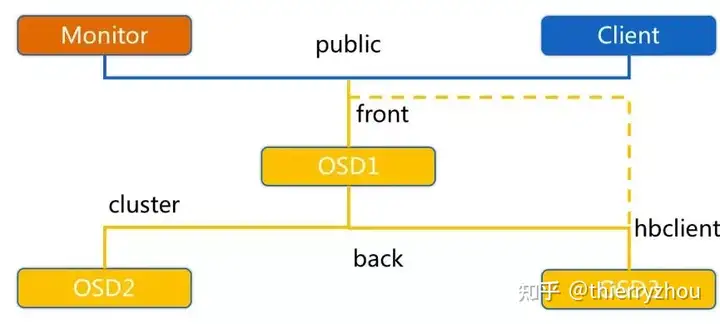
OSD 上电的过程中有一个非常关键的步骤,创建用于在集群中通信的 messenger 对象,其底层封装了 RPC 协议通信接口。这些messager 对应监听 public、cluster、front 和 back 四个端口:
public 端口:监听来自 Monitor 和 Client 的连接。
cluster 端口:监听来自 OSD Peer 的连接。
front 端口:供客户端连接集群使用的网卡, 这里临时给集群内部之间进行心跳。
back 端口:供客集群内部使用的网卡。集群内部之间进行心跳。
而这些在 messager 对象中,有四个用于心跳通信的async messenger。
int main(int argc, const char **argv){
// ...
// messengers
std::string msg_type = g_conf().get_val<std::string>("ms_type");
std::string public_msg_type =
g_conf().get_val<std::string>("ms_public_type");
std::string cluster_msg_type =
g_conf().get_val<std::string>("ms_cluster_type");
public_msg_type = public_msg_type.empty() ? msg_type : public_msg_type;
cluster_msg_type = cluster_msg_type.empty() ? msg_type : cluster_msg_type;
uint64_t nonce = Messenger::get_pid_nonce();
// 集群消息
Messenger *ms_public = Messenger::create(g_ceph_context, public_msg_type,
entity_name_t::OSD(whoami), "client", nonce);
Messenger *ms_cluster = Messenger::create(g_ceph_context, cluster_msg_type,
entity_name_t::OSD(whoami), "cluster", nonce);
// 心跳消息
Messenger *ms_hb_back_client = Messenger::create(g_ceph_context, cluster_msg_type,
entity_name_t::OSD(whoami), "hb_back_client", nonce);
Messenger *ms_hb_front_client = Messenger::create(g_ceph_context, public_msg_type,
entity_name_t::OSD(whoami), "hb_front_client", nonce);
Messenger *ms_hb_back_server = Messenger::create(g_ceph_context, cluster_msg_type,
entity_name_t::OSD(whoami), "hb_back_server", nonce);
Messenger *ms_hb_front_server = Messenger::create(g_ceph_context, public_msg_type,
entity_name_t::OSD(whoami), "hb_front_server", nonce);
Messenger *ms_objecter = Messenger::create(g_ceph_context, public_msg_type,
entity_name_t::OSD(whoami), "ms_objecter", nonce);
if (!ms_public || !ms_cluster || !ms_hb_front_client || !ms_hb_back_client || !ms_hb_back_server || !ms_hb_front_server || !ms_objecter)
forker.exit(1);
ms_cluster->set_cluster_protocol(CEPH_OSD_PROTOCOL);
ms_hb_front_client->set_cluster_protocol(CEPH_OSD_PROTOCOL);
ms_hb_back_client->set_cluster_protocol(CEPH_OSD_PROTOCOL);
ms_hb_back_server->set_cluster_protocol(CEPH_OSD_PROTOCOL);
ms_hb_front_server->set_cluster_protocol(CEPH_OSD_PROTOCOL);
dout(0) << "starting osd." << whoami
<< " osd_data " << data_path
<< " " << ((journal_path.empty()) ?
"(no journal)" : journal_path)
<< dendl;
uint64_t message_size =
g_conf().get_val<Option::size_t>("osd_client_message_size_cap");
boost::scoped_ptr<Throttle> client_byte_throttler(
new Throttle(g_ceph_context, "osd_client_bytes", message_size));
uint64_t message_cap = g_conf().get_val<uint64_t>("osd_client_message_cap");
boost::scoped_ptr<Throttle> client_msg_throttler(
new Throttle(g_ceph_context, "osd_client_messages", message_cap));
// All feature bits 0 - 34 should be present from dumpling v0.67 forward
uint64_t osd_required =
CEPH_FEATURE_UID |
CEPH_FEATURE_PGID64 |
CEPH_FEATURE_OSDENC;
ms_public->set_default_policy(Messenger::Policy::stateless_registered_server(0));
ms_public->set_policy_throttlers(entity_name_t::TYPE_CLIENT,
client_byte_throttler.get(),
client_msg_throttler.get());
ms_public->set_policy(entity_name_t::TYPE_MON,
Messenger::Policy::lossy_client(osd_required));
ms_public->set_policy(entity_name_t::TYPE_MGR,
Messenger::Policy::lossy_client(osd_required));
ms_cluster->set_default_policy(Messenger::Policy::stateless_server(0));
ms_cluster->set_policy(entity_name_t::TYPE_MON, Messenger::Policy::lossy_client(0));
ms_cluster->set_policy(entity_name_t::TYPE_OSD,
Messenger::Policy::lossless_peer(osd_required));
ms_cluster->set_policy(entity_name_t::TYPE_CLIENT,
Messenger::Policy::stateless_server(0));
ms_hb_front_client->set_policy(entity_name_t::TYPE_OSD,
Messenger::Policy::lossy_client(0));
ms_hb_back_client->set_policy(entity_name_t::TYPE_OSD,
Messenger::Policy::lossy_client(0));
ms_hb_back_server->set_policy(entity_name_t::TYPE_OSD,
Messenger::Policy::stateless_server(0));
ms_hb_front_server->set_policy(entity_name_t::TYPE_OSD,
Messenger::Policy::stateless_server(0));
ms_objecter->set_default_policy(Messenger::Policy::lossy_client(CEPH_FEATURE_OSDREPLYMUX));
//...
}
由于所有OSD进程处于对等地位,所以每个osd在创建了client的同时也创建了server。至于,front和back和ceph的网络规划有关,ceph将osd间的副本数据、迁移数据的传输交由cluster network,将client和ceph后端的数据传输交由public network,如下图:
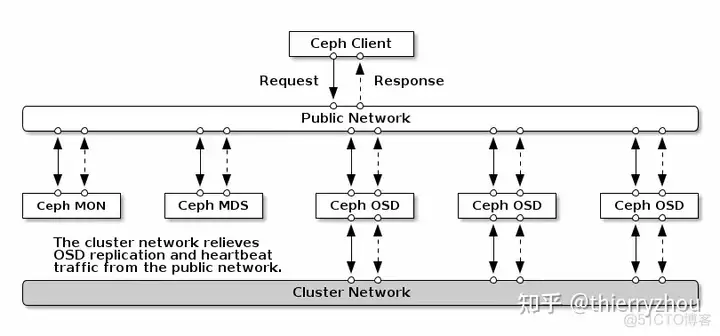
front用的是public network,用于检测客户端网络连接问题,back用的是cluster network。
OSD 之间相互心跳检测
a. 同一个 PG 内 OSD 互相心跳,他们互相发送 PING/PONG 信息。
b. 每隔 6s 检测一次(实际会在这个基础上加一个随机时间来避免峰值)。
c. 20s 没有检测到心跳回复,加入 failure 队列。
OSD 报告给 Monitor
a. OSD 有事件发生时(比如故障、PG 变更)。
b. 自身启动 5 秒内。
c. OSD 周期性的上报给 Monitor。
d. OSD 检查 failure_queue 中的伙伴 OSD 失败信息。
e. 向 Monitor 发送失效报告,并将失败信息加入 failure_pending 队列,然后将其从 failure_queue 移除。
f. 收到来自 failure_queue 或者 failure_pending 中的 OSD 的心跳时,将其从两个队列中移除,并告知 Monitor 取消之前的失效报告。
g. 当发生与 Monitor 网络重连时,会将 failure_pending 中的错误报告加回到 failure_queue 中,并再次发送给 Monitor。
h. Monitor 统计下线 OSD。
i. Monitor 收集来自 OSD 的伙伴失效报告。
j. 当错误报告指向的 OSD 失效超过一定阈值,且有足够多的 OSD 报告其失效时,将该 OSD 下线。
OSD 故障检测
集群通过一下三种方式检测OSD故障(下电):
- OSD自主上报状态,优雅下电,Monitor 将 OSD 标记为 down。
- OSD检测到伙伴OSD返回ECONNREFUSED错误,则设置Force/ Immediate标识,向Monitor上报错误。当 该 OSD 积累的有效错误投票的票数达到阈值(默认2),Monitor 将 OSD 标记为 down,投票采用少数服从多数的方式,并且来自某个最小故障域的主机所有OSD针对候选OSD的投票算1票。
- Monitor检测到与OSD之间心跳超时,失联的 OSD 被标记为 down。
每个OSD周期性(默认300秒)的向Monitor发送Beacon消息证明自己存活,如果Monitor一段时间(默认900秒)没收到OSD的Beacon,就标记OSD为down。OSDdown后超过600S,会被标记为out(Monitor通过 一个名为 mon_osd_down_out_subtree_limit 的配置项来限制自动数据迁移的粒度,例如设置为主机,则 当某个主机上的OSD全部宕掉时,这些OSD不再会被自动标记为Out,也就无法自动进行数据迁移,从而避免 数据迁移风暴)
通过心跳被检测到的所有故障都会先记录在 osdmap 中,后报告到Monitor,然后扩散至集群,其他OSD收到消息后采取对应的措施。
1. OSD 如何选择伙伴 OSD?
- 选择与当前 OSD 所在处的 PG 的 OSD 表中,其他处于 Up + Activing 的 OSD
- 选择在编号上与当前 OSD 临近(前一个以及后一个)处于 Up + Activing 的 OSD
- 如果 OSD 的心跳伙伴 OSD 个数小于预期(一般为10个),则依次原则在编号上与当前 OSD 临近且处于 Up + Activing 的 OSD,直到编号的最小(最大)值。
2. 客户端如何感知 OSD 状态变化?
客户端读写前会先从Monitor中获取到 PGMap 以及 OSDMap,PGMap 根据 version 信息判断 Map 是否过期如果过期则重启更新 Map,OSDMap 则是根据 epoch 信息来判断。
Ceph 心跳检测总结
及时:
伙伴 OSD 可以在秒级发现节点失效并汇报 Monitor,并在几分钟内由 Monitor 将失效 OSD 下线。
适当的压力:
由于有伙伴 OSD 汇报机制,Monitor 与 OSD 之间的心跳统计更像是一种保险措施,因此 OSD 向 Monitor 发送心跳的间隔可以长达 600 秒,Monitor 的检测阈值也可以长达 900 秒。Ceph 实际上是将故障检测过程中中心节点的压力分散到所有的 OSD 上,以此提高中心节点 Monitor 的可靠性,进而提高整个集群的可扩展性。
容忍网络抖动:
Monitor 收到 OSD 对其伙伴 OSD 的汇报后,并没有马上将目标 OSD 下线,而是周期性的等待几个条件:
目标 OSD 的失效时间大于通过固定量 osd_heartbeat_grace 和历史网络条件动态确定的阈值。
来自不同主机的汇报达到 mon_osd_min_down_reporters。
满足前两个条件前失效汇报没有被源 OSD 取消。
扩散:
作为中心节点的 Monitor 并没有在更新 OSDMap 后尝试广播通知所有的 OSD 和 Client,而是惰性的等待 OSD 和 Client 来获取。以此来减少 Monitor 压力并简化交互逻辑。
Ceph PG 状态分析
active + clean是 PG 的健康状态,然而PG也会生病,有的是普通的咳嗦,有的则可能是肺炎,有的则是肺癌,接下来我们分析下常见的异常状态原因:
Degraded
降级就是在发生了一些故障比如 OSD 挂掉之后,ceph 将这个 OSD 上的所有 PG 标记为 degraded,但是此时的集群还是可以正常读写数据的,但是需要做一些额外的标记和处理,因此虽然降级并不是严重的问题,仍会造成读写性能的下降。一遍undersized 与 degraded 是成对出现的。例如 replicas 为3,min_osd 为2,undersized + degraded 表示当前PG中活跃的 OSD 为2。
Peered
peered,我们这里可以将它理解成它在等待其他兄弟姐妹上线,这里也就是osd.4和osd.7的任意一个上线就可以去除这个状态了,处于peered状态的PG是不能响应外部的请求的,外部就会觉得卡卡的。
Stale
Stale可能产生的原因包括:mon检测到当前PG的Primary所在的osd宕机;Primary超时未向mon上报pg相关的信息(例如网络阻塞);PG内三个副本都挂掉的情况。
PG 处于Stale状态时,无法对外服务,客户端的 IO 则是会被夯住,等待 PG 状态恢复。
Remapped
当处于down状态的OSD,被标记为out状态,这个PG 就会基于 CRUSH 算法重新计算OSD列表,这个过程就是 remapped 状态。创建列表只是相当于创建了一个目录,丢失的数据是要从正常的OSD中拷贝到新的OSD中,处于回填状态的PG就会被标记为backfilling。这个过程 remapped 状态不会消失,所以此时异常的PG处于remapped+backfilling状态时。
Backfill
正在后台填充态。 backfill 是r ecovery 的一种特殊场景,指 peering 完成后,如果基于当前权威日志无法对Up Set当中的某些PG实例实施增量同步(例如承载这些PG实例的OSD离线太久,或者是新的OSD加入集群导致的PG实例整体迁移) 则通过完全拷贝当前Primary所有对象的方式进行全量同步。
Inconsistent
数据不一致。 Inconsistent 有两种产生方式:一种是 OSD 异常后重新上电时,在Peering过程中发现数据不一致,由primary OSD 将PG状态修改为 inconsistent;另一种是 使用 ceph osd repair http://pg.XXX,主动去扫描 PG 的日志和数据内容,发现问题后同样也是由 primary OSD 修改状态。
Incomplete
Peering过程中, 由于 a. 无非选出权威日志 b. 通过choose_acting选出的Acting Set后续不足以完成数据修复,导致Peering无非正常完成。
Ceph PG 状态对照表
| 状态 | 描述 |
|---|---|
| active | 当前拥有最新状态数据的pg正在工作中,能正常处理来自客户端的读写请求。 |
| inactive | 正在等待具有最新数据的OSD出现,即当前具有最新数据的pg不在工作中,不能正常处理来自客户端的读写请求。 |
| activating | Peering 已经完成,PG 正在等待所有 PG 实例同步并固化 Peering 的结果 (Info、Log 等) |
| clean | pg所包含的object达到指定的副本数量,即object副本数量正常 |
| unclean | PG所包含的object没有达到指定的副本数量,比如一个PG没在工作,另一个PG在工作,object没有复制到另外一个PG中。 |
| peering | PG所在的OSD对PG中的对象的状态达成一个共识(维持对象一致性),对象同步中,此时客户端IO排队不可读写。 |
| peered | peering已经完成,但pg当前acting set规模小于存储池规定的最小副本数(min_size) |
| degraded | 主osd没有收到副osd的写完成应答,比如某个osd处于down状态 |
| stale | 主osd未在规定时间内向mon报告其pg状态,或者其它osd向mon报告该主osd无法通信 |
| inconsistent | PG中存在某些对象的各个副本的数据不一致,原因可能是数据被修改 |
| incomplete | peering过程中,由于无法选出权威日志,通过choose_acting选出的acting set不足以完成数据修复,导致peering无法正常完成 |
| repair | pg在scrub过程中发现某些对象不一致,尝试自动修复 |
| undersized | pg的副本数少于pg所在池所指定的副本数量,一般是由于osd down的缘故 |
| scrubbing | pg对对象meta的一致性进行扫描 |
| deep | pg对对象数据的一致性进行扫描 |
| creating | pg正在被创建 |
| recovering | pg间peering完成后,对pg中不一致的对象执行同步或修复,一般是osd down了或新加入了osd |
| recovering-wait | 等待 Recovery 资源预留 |
| backfilling | 一般是当新的osd加入或移除掉了某个osd后,pg进行迁移或进行全量同步 |
| down | 包含必备数据的副本挂了,pg此时处理离线状态,不能正常处理来自客户端的读写请求 |
| remapped | 重新映射态。PG 活动集任何的一个改变,数据发生从老活动集到新活动集的迁移。在迁移期间还是用老的活动集中的主 OSD 处理客户端请求,一旦迁移完成新活动集中的主 OSD 开始处理 |
| misplaced | 有一些回填的场景:PG被临时映射到一个OSD上。而这种情况实际上不应太久,PG可能仍然处于临时位置而不是正确的位置。这种情况下个PG就是misplaced。这是因为正确的副本数存在但是有个别副本保存在错误的位置上。 |