ceph运维大宝剑之pg unknow
写在前面
本篇写的是一个简单的问题。
近日社区有同学问我,集群有slow request,pg不正常,怎么排查,这其实是一个新手容易遇到的问题,涉及的概念比较基本,征得其本人同意后,有了这篇分享
现象
一开始看到集群的现象是slow request,集群有pg unknow
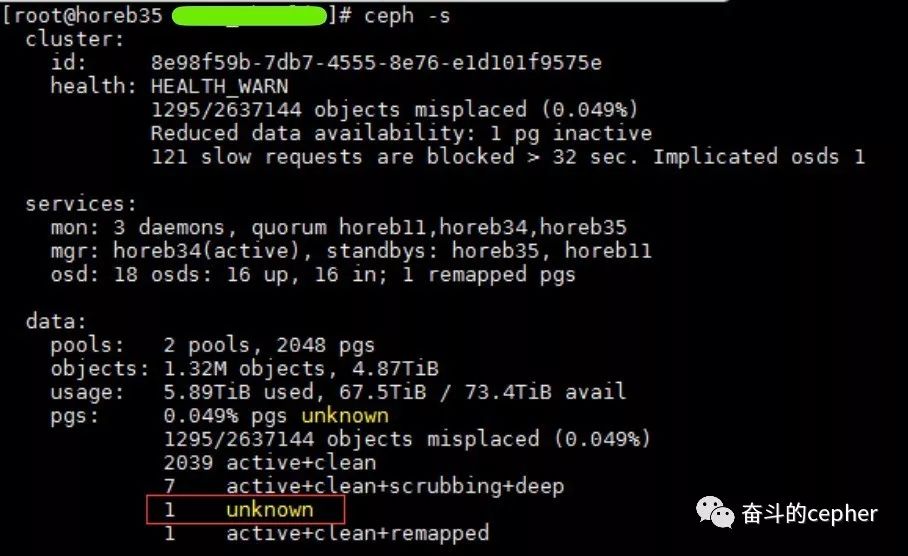
slow request的原因有很多,这里的slow可以确定是卡在了unknow的pg上,接下来,这位同学使用upmap命令,尝试将这个unknow的pg移动到别的osd上,企图复活这个pg,未果
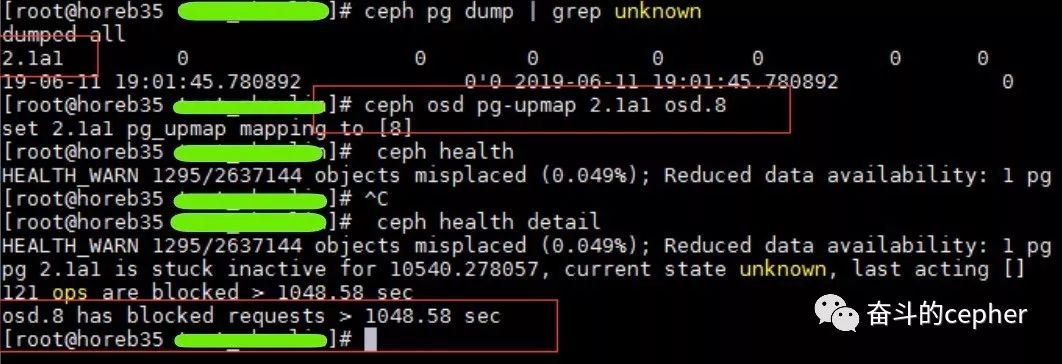
与此同时,osd.8上有大量的slow request日志,尝试repair这个pg,未果
接着,从该同学给出的osd tree中似乎找到了答案
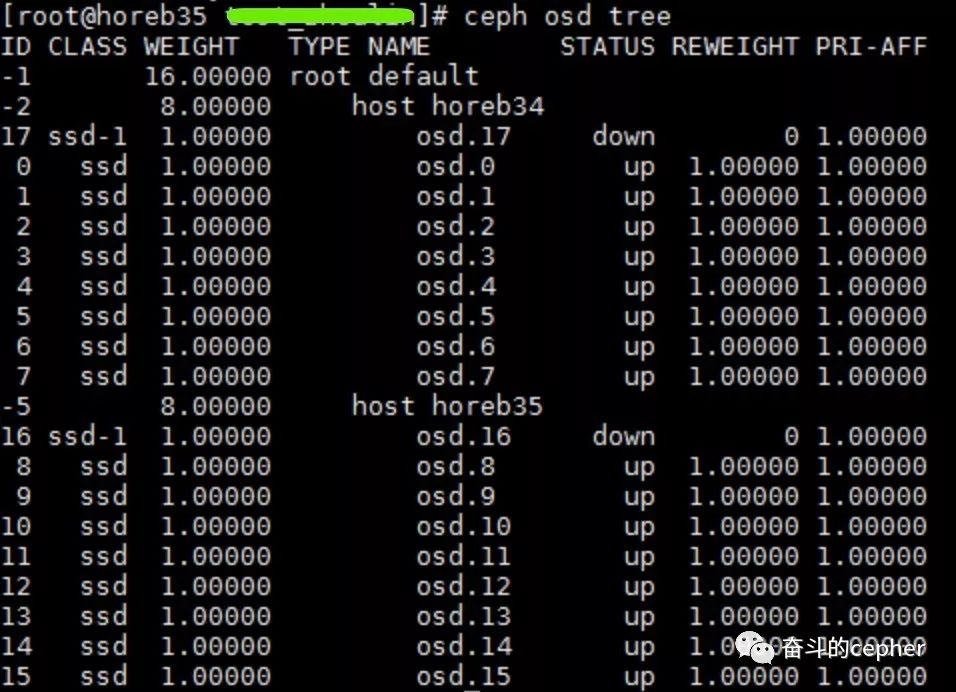
哎哟,这不是两副本吗?怎么挂了两个故障域的osd了??这种情况下,pg当然会unknow啦,因为ceph根本不知道这个pg现在是什么情况,为什么?
原理说明
在ceph的crushmap中,有个概念叫故障域,它定义了若干个不相同的区域,这些区域中的osd负责存储数据的不同副本(数据存在pg中),也就是,不同的数据副本(EC也算)会且只会分布在不同的故障域中
如本次故障的环境,两副本,故障域是host,这就是说,数据的两个副本只能分别在这两个host的osd中,当其中一个host有osd挂掉时,如osd.17,这个osd上的副本就暂时丢失了,不用怕,因为另外一个host的其中一个osd还保留另外一份副本
但是,在这个环境中,当osd.17挂掉后,数据还没完成恢复,此时另外一个host又挂掉一个osd.16,真巧,这两个osd上有一个共同的pg,这个pg在第一个osd.17挂掉后没有来得及将数据迁移,最后一个副本所在的osd.16又挂了,这时,这个pg只剩下0副本了
发生这种情况时,ceph也不知道怎么办了,因为0副本的情况下,数据没法访问,没法读取,也没法校验,所以会unknow
这种情况在2副本环境比较容易发生,在3副本环境发生的概率就小很多,因为要出现0副本,必须挂掉3个故障域的osd才有可能发生,概率是比较低的
处理办法
在要求保证数据可靠性的前提下,恢复这个pg的方法就是要让其中一个挂掉的osd正常起来,向集群报告那个unknow状态的pg的情况,然后等待数据恢复
注意
在没有把握的情况下,强烈不建议对pg进行操作,例如删掉pg再重建!删掉pg再重建,集群可以恢复到健康水平,但是,被删掉的pg上的数据就永久丢失了!如果pg的数据可以不要,何不整个pool都删掉呢?