Ceph 的数据回填和恢复
ceph在增加osd的时候会触发backfill,让数据得到平均,触发数据的迁移
ceph在移除osd的时候需要在节点上进行数据的恢复,也有数据的迁移和生成
只要是集群里面有数据的变动就会有网卡流量,cpu,内存等资源的占用,并且最重要的是还有磁盘的占用,这个客户端也是需要对磁盘进行访问的,当请求出现碰撞的时候,肯定会比正常的情况下要慢很多,而且还有可能因为资源方面的原因而引起机器down机等异常状况的出现
主要引起的问题可能:
- 在peering的时候 block 了IO请求
- 在backfill的引起了slow requests
- 上面的两个情况会引起客户端的降速和出现soft lockup
这个在一般情况下会出现不同的需求:
- 慢点可以一定不能出问题,不能中断业务
- 越快迁移完越好,早点结束维护服务
- 需要又快又不能影响业务
这个需要根据自己可以掌控的程度来进行控制,首先环境的不同,影响不同,迁移数据量,网卡的带宽都是重要的影响因素,从整体上可以根据自己的环境按照上面的三个要求中的一个进行控制
上面的三种情况:
第一个慢点迁移不能出问题,这个处理方式比较简单,直接将相关参数控制到最低的值,这个能保证业务的影响最低,但是带来的影响就是迁移需要很久的时间,可能长达几十个小时
第二个越快越好就是用默认的参数或者加大参数,然后观察这个迁移过程中的资源的占用情况
第三个就是需要在自己的环境下进行多测试验证这个参数,本篇主要就是根据思科的测试出来的参数进行分析
下面的参数是思科测试出来的值:
osd recovery max active = 3 (default : 15)
osd recovery op priority = 3 (default : 10)
osd max backfills = 1 (default : 10)
测试过程的数据图
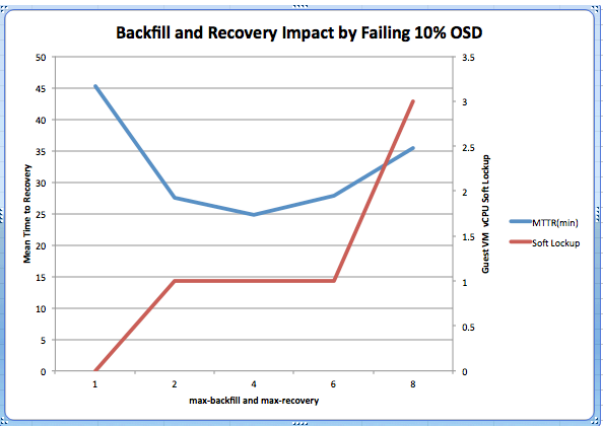
这个图开始的时候我也没太明白,后来多看下就理解了,实际上在很多情况下,一个因素的变化是会引起其他两个因素的变化,而这两个因素是一个正面的因素和一个负面的因素,而找到这个平衡值就是最优的情况,在这里的因素包括:
max-backfill和max-recovery :迁移相关参数
MTTR(mean time to recovery):失效恢复时间,也就是迁移完成
Soft Lockup:前面虚拟机出现的soft lockup,也可以理解为对前端的影响
测试环境一致,都是 down 掉10%的osd进行恢复:
在迁移参数最低的时候,没有出现soft lockup ,也就是最低迁移参数的时候,影响最小,恢复使用了45分钟
随着迁移相关参数调大的时候,迁移的时间的曲线是先降低,在到达一定的值后又开始增加(这个地方可能是迁移过大出现了前端io锁住,然后影响了迁移速度)
随着迁移相关参数的调大,出现soft lockup的情况是增加的
从测试的曲线来看,在2-6之间是出现的最优值,也就是出现异常的情况概率最低,并且迁移速度最快,最终选择了一组最优的值 :
osd recovery max active = 3 (default : 15)
osd recovery op priority = 3 (default : 10)
osd max backfills = 1 (default : 10)
这个值是思科的测试出来的值,这个值可以根据自己的需要进行取用,大概的情况是这样
- 完全无法把控就把参数调整到最低
- 使用思科的推荐值
- 根据自己的环境测出自己环境的最优值
很多参数是别人根据自己的环境测试出来的,很多情况并不是通用的,得到别人测试的思路是最重要的,然后消化后自己根据自己的需要得出自己的值