Ceph之osd扩容和换盘
Ceph之osd扩容和换盘
目录
一、osd扩容
1.1 osd横向扩容(scale out)
简单理解,横向扩容就是通过增加节点来达到增加容量的目的,大概操作流程如下:
- 参考 [部署ceph集群 (Nautilus版)](https://lvjianzhao.gitee.io/lvjianzhao/2021/02/21/部署ceph Nautilus版/#more) 对新节点进行初始化、配置yum源、时间同步,安装基础工具,集群间的主机名互相可解析,ceph-deploy节点可以免密登录到新节点等操作。
- 执行命令
ceph-deploy osd create --data {data-disk} {node-name}同步配置文件ceph -s查看集群状态,如果无误,添加osd完成。
1.2 osd纵向扩容(scale up)
纵向扩容:通过增加现有节点的硬盘(OSD)来达到增加容量的目的。
1.2.1 清理磁盘数据
如果目标磁盘有分区表,请执行下列命令进行删除分区信息,对应的数据也将会被删除。
$ ceph-deploy disk zap ceph-node-11 /dev/sdc |
|
# 后面跟的是节点名称 磁盘名称 |
1.2.2 加入新的osd
$ ceph-deploy osd create ceph-node-11 --data /dev/sdc |
1.2.3 确认ods已扩容
$ ceph -s |
|
cluster: |
|
id: b5ae2882-7ec6-46cd-b28e-6d7527e5deb3 |
|
health: HEALTH_OK |
|
services: |
|
mon: 3 daemons, quorum ceph-node-11,ceph-node-12,ceph-node-13 (age 3h) |
|
mgr: ceph-node-11(active, since 3h), standbys: ceph-node-12, ceph-node-13 |
|
mds: cephfs-demo:1 {0=ceph-node-11=up:active} 2 up:standby |
|
osd: 4 osds: 4 up (since 6m), 4 in (since 6m) # 已经增加一个osd |
|
rgw: 1 daemon active (ceph-node-11) |
|
task status: |
|
scrub status: |
|
mds.ceph-node-11: idle |
|
data: |
|
pools: 9 pools, 288 pgs |
|
objects: 222 objects, 8.3 KiB |
|
usage: 4.1 GiB used, 396 GiB / 400 GiB avail |
|
pgs: 6.944% pgs unknown |
|
268 active+clean |
|
20 unknown |
1.3 ceph osd数据重新分布
当有新的osd加入集群或者移除了osd,就会把状态上报给Monitor,Monitor知道了osd map发生了变化就会触发rebalancing,确保pg能够平滑的移动到各个osd上。以pg为整体进行数据重平衡,重平衡的过程中可能会影响性能。一次性加入的osd越多,数据rebalancing就越频繁,业务也可能因此受到影响。生产环境中,强烈建议一次只添加一个osd,最大限度的减少性能和业务的影响。
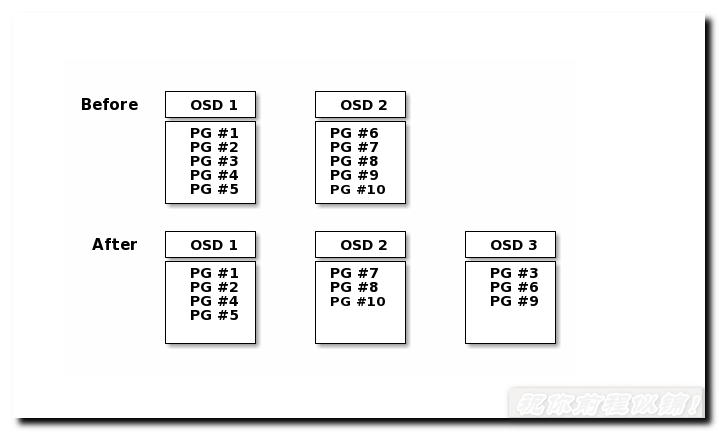
1.3.1 临时关闭rebalance
当在做rebalance的时候,每个osd都会按照osd_max_backfills指定数量的线程来同步,如果该数值比较大,同步会比较快,但是会影响部分性能;另外数据同步时,是走的cluster_network,而客户端连接是用的public_network,生产环境建议这两个网络用万兆网络,较少网络传输的影响!
$ ceph --admin-daemon /var/run/ceph/ceph-osd.0.asok config show | grep max_backfills |
|
"osd_max_backfills": "1", # osd_max_backfills默认还是比较小的 |
同样,为了避免业务繁忙时候rebalance带来的性能影响,可以对rebalance进行关闭;当业务比较小的时候,再打开:
$ ceph osd set norebalance # 设置标志位 |
|
$ ceph osd set nobackfill # 关闭数据填充 |
|
$ ceph -s # 查看集群状态 |
|
cluster: |
|
id: b5ae2882-7ec6-46cd-b28e-6d7527e5deb3 |
|
health: HEALTH_WARN |
|
nobackfill,norebalance flag(s) set |
|
# 有此信息 |
1.3.2 开启rebalance
$ ceph osd unset nobackfill |
|
$ ceph osd unset norebalance |
|
$ ceph -s # 确认集群状态为ok |
|
cluster: |
|
id: b5ae2882-7ec6-46cd-b28e-6d7527e5deb3 |
|
health: HEALTH_OK |
二、osd缩容
当osd对应的硬件磁盘设备损坏或者其他情况,我们需要将磁盘对应的osd剔除集群,进行维护。那么应该怎么做呢?
$ ceph osd perf # 检查磁盘延迟 |
|
osd commit_latency(ms) apply_latency(ms) |
|
3 0 0 |
|
2 0 0 |
|
1 0 0 |
|
0 0 0 |
|
# 如果磁盘有坏道,那么其延迟可能会很高 |
|
# 严重的话,会影响我们整个ceph集群的性能,故需要剔除出去 |
|
$ systemctl stop ceph-osd@4 # 停掉一个osd守护进程 |
|
$ ceph osd tree # 其状态为down,表示不可用 |
|
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF |
|
-1 0.39075 root default |
|
-3 0.19537 host ceph-node-11 |
|
0 hdd 0.09769 osd.0 up 1.00000 1.00000 |
|
3 hdd 0.09769 osd.3 down 1.00000 1.00000 |
|
-5 0.09769 host ceph-node-12 |
|
1 hdd 0.09769 osd.1 up 1.00000 1.00000 |
|
-7 0.09769 host ceph-node-13 |
|
2 hdd 0.09769 osd.2 up 1.00000 1.00000 |
2.1 剔除osd节点
$ ceph osd out osd.3 # 从crush map中移除osd |
|
$ ceph osd tree # down掉的节点权重已变为 0 |
|
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF |
|
-1 0.39075 root default |
|
-3 0.19537 host ceph-node-11 |
|
0 hdd 0.09769 osd.0 up 1.00000 1.00000 |
|
3 hdd 0.09769 osd.3 down 0 1.00000 |
|
-5 0.09769 host ceph-node-12 |
|
1 hdd 0.09769 osd.1 up 1.00000 1.00000 |
|
-7 0.09769 host ceph-node-13 |
|
2 hdd 0.09769 osd.2 up 1.00000 1.00000 |
|
$ ceph osd crush remove osd.3 # 移除 |
|
# 经过上面操作后,已经删除了 |
|
# 但执行 ceph osd tree 命令还可以查看到该osd,需要执行如下指令进行删除 |
|
$ ceph osd rm osd.3 |
|
# 删除认证信息 |
|
$ ceph auth list | grep -A 4 osd.3 # 查看是否还有其认证信息 |
|
installed auth entries: |
|
osd.3 |
|
key: AQCAJ89gtihHMhAAjOWdLs+otDICt2EkV6uG4A== |
|
caps: [mgr] allow profile osd |
|
caps: [mon] allow profile osd |
|
caps: [osd] allow * |
|
$ ceph auth rm osd.3 # 删除认证信息 |
|
updated |
|
$ ceph auth list | grep -A 4 osd.4 # 确认已删除 |
|
installed auth entries: |
至此,osd剔除集群完成。