通过jenkins了解CI/CD
本文并没有什么结论性的东西,只是分析一下我遇到的问题与思路,希望能得到读者们更多的经验分享。
本文也不会对jenkins面面俱到,仅仅提供学习思路和路线。
背景
以前在百度工作时,公司是提供了CI/CD平台来完成版本的发布上线全流程,虽然那时候用的比较初级。
对于百度CI/CD平台来说,无论你的代码在什么分支,提交后会通知到CI平台,而后续的流程完全可以通过UI(或者配置文件)进行订制,以我之前的工作经验来说:
- 先执行单元测试
- 将代码编译或者打包
- 发送邮件给QA并暂停CI流程
- QA手动的将打包文件部署到测试环境进行验证
- QA回到CI平台触发流程继续,也就是通过了测试
- RD(研发)进入PAAS上线平台,勾选要上线的版本,并发起上线申请
- BOSS/OP(上级)确认上线申请,上线平台创建若干服务容器,将对应版本的打包代码释放到容器内的特定目录
- 上线平台切换负载均衡,流量切换到新版本容器,完成上线
你会发现,CI/CD更加在意每次提交的产出,是测试失败还是测试成功,成功发布的版本可以上线,失败的发布不能上线。
同时发现,CI/CD比较不在意版本库的最新状态,发布到线上的一定是通过CI流程的产出物,无论版本库中最新代码是否处于编译fail状态,我们都可以将最近一次发布成功的产物放心上线,我认为这是CI/CD的一个重要思想。
另外,CI/CD并不意味着不使用分支或者说主张单分支开发,我认为分支管理是另外一套东西,不应该与CI/CD混为一谈。
CI/CD可以对不同的分支订制不同的CI流程,比如:dev分支不需要QA测试环节。不同的分支提交,最终在CI/CD平台都对应一次唯一的发布流程,它们可能成功可能失败,成功则有对应的打包产物。而CI/CD只需要做好自己的工作即可,分支管理是另外一套工作,两者并不矛盾。
关于CI/CD的思想方面,我建议阅读阮一峰的《持续集成是什么?》
关于jenkins
它的原理不难理解,下面逐步描述一下。
形态
jenkins是java开发的,启动后是一个单点进程,提供一个WEB页面进行可视化操作。
数据它直接维护在本地磁盘上,所以不需要配置数据库。
它直接网络对接git或者svn这种版本管理,进行代码的更新检测以及下载。
当它检测到代码提交后,会直接在进程内完成代码的更新,并执行用户自定义的一系列CI流程。
CI流程是用户通过一个特殊格式的配置文件Jenkinsfile定义的,每个项目可以只定义一个Jenkinsfile,或者为项目下的每个分支分别定义不同的Jenkinsfile,从而实现不同的CI流程。
jenkins也支持多机部署进行性能扩展,不过貌似没有太多介绍。
工作模式
jenkins采用pipeline,也就是流水线式的工作原理。其实并不是什么高大上的东西,意思就是你可以在Jenkinsfile中连续配置若干个步骤,当代码有变化时Jenkins会依次执行这些步骤。当然,Jenkins实际上最新支持了一定程度的并行语法,可以实现几个步骤同时发生。
创建项目时,有一个类型选择界面,我体验了一下pipeline和multibranch pipeline,它们都基于Jenkinsfile配置工作,但是后者能够识别同一个项目的多个分支并且每个分支独立配置独立执行。
创建项目首先选择类型,这里我选择pipeline,它无法识别项目下的子目录(分支),只要项目下任意分支发生改变,就会触发CI流程:
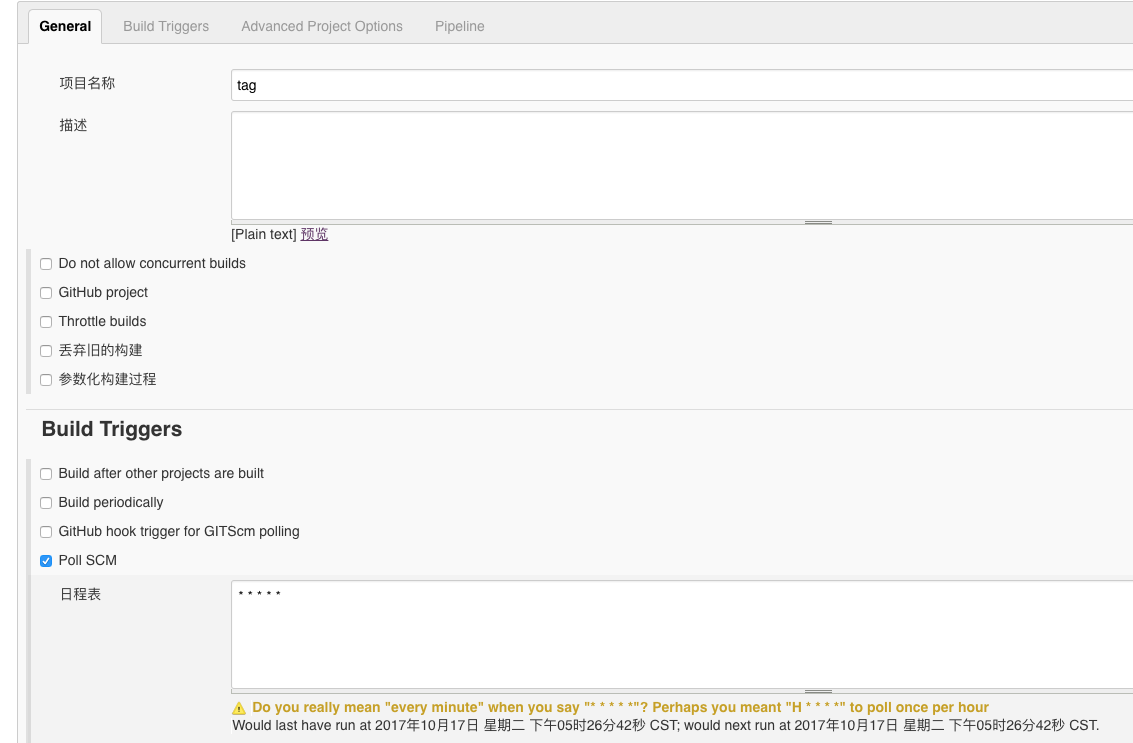
pollSCM是检查源码变化的间隔周期,如果你对版本库没有操控权(比如OP在维护),那么只能通过定期检测版本库去判断是否有更新,而一个更加实时的方案应该是版本库提交后hook主动触发一下jenkins。
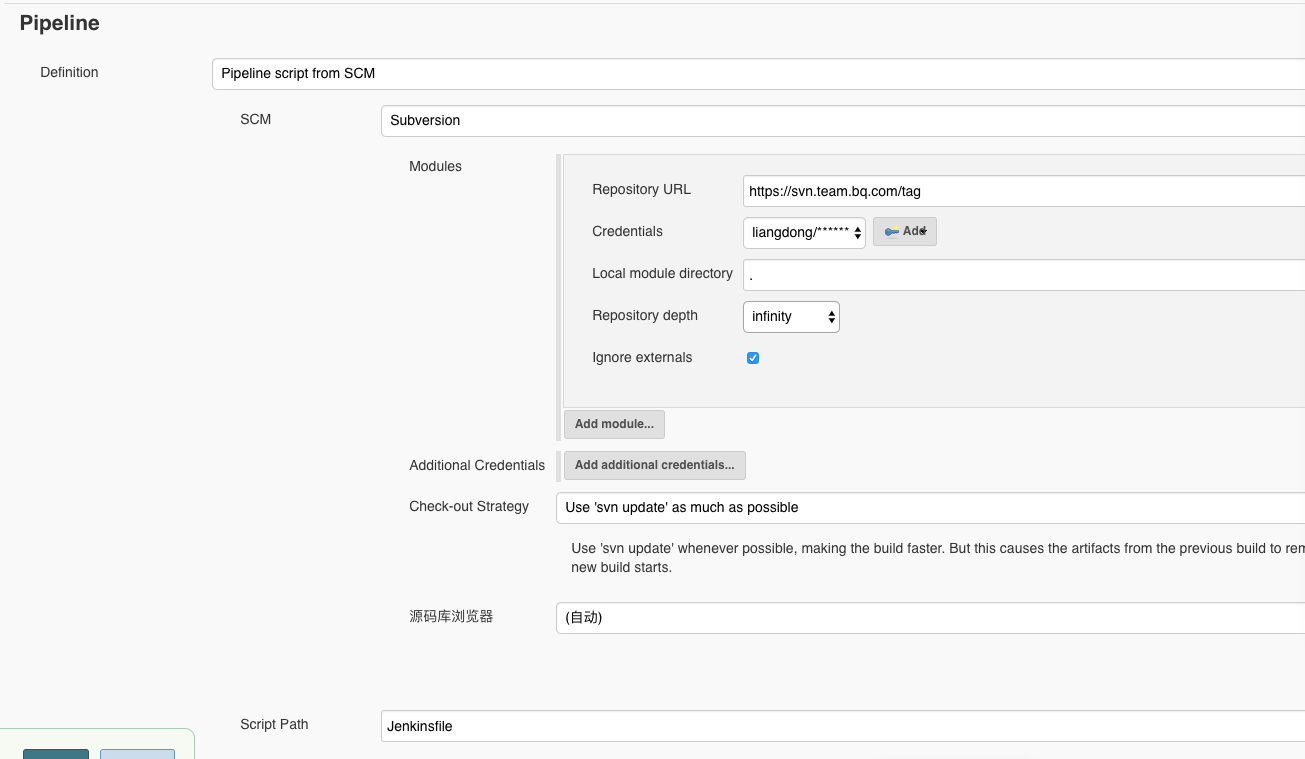
接下来,我需要配置这个项目的SVN路径、账号密码等信息,指定采用项目根目录下的Jenkinsfile作为CI流程的配置。
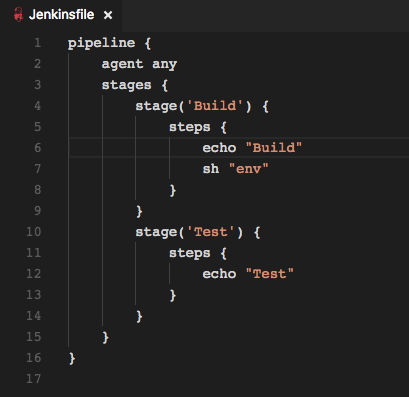
这个Jenkinsfile上传在项目的版本库里,当前它的内容很简单,每个stage是一个环节,内部可以定义若干步骤step,而step最简单的可以指定执行某个shell命令,所有stage/step将依次执行,这就是jenkins提供给我们的一个基础能力。
当我们提交任意修改到项目后,1分钟内jenkins将轮询发现我们的提交,并触发这样的一个CI流程,相关日志可以在线查看:
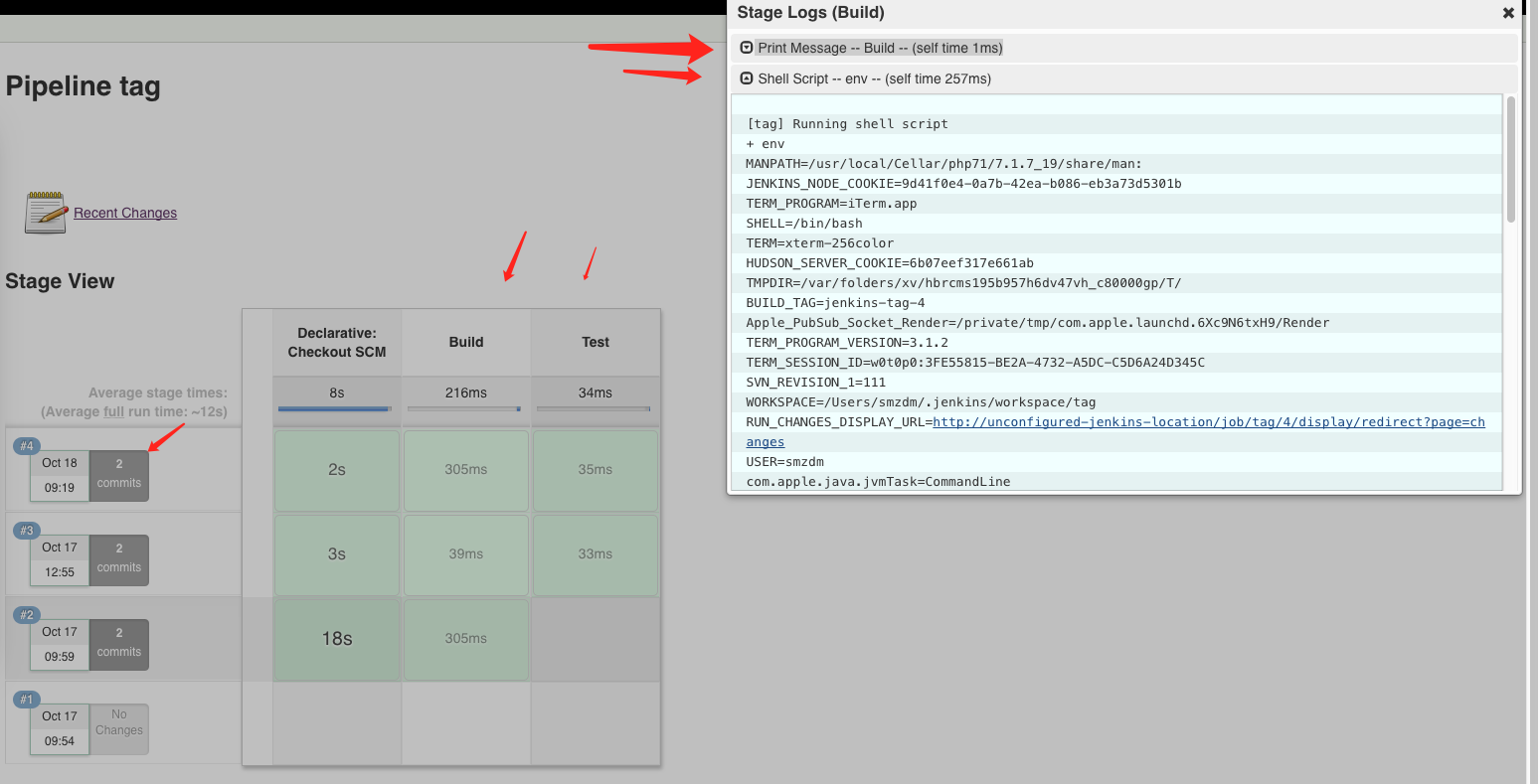
从打印的env中可以看到:
|
1
|
WORKSPACE=/Users/smzdm/.jenkins/workspace/tag
|
表示整个JOB作业是在这个目录下发生的:
|
1
2
3
4
5
|
liangdong:tag smzdm$ ll /Users/smzdm/.jenkins/workspace/tag
total 8
-rw-r--r-- 1 smzdm staff 265 10 18 09:19 Jenkinsfile
drwxr-xr-x 4 smzdm staff 136 10 17 09:59 doc
drwxr-xr-x 6 smzdm staff 204 10 17 10:00 src
|
基础概念
首先呢,最重要的是了解Jenkinsfile的语法,这决定了你可以把jenkins基本用法掌握,我直接把jenkins的官方文档读了一下,语法方面最详细的介绍在这个页面。
其次呢,默认jenkins是在$HOME/.jenkins目录下维护各种数据的,我们配置的每个项目每次CI都会在$HOME/.jenkins/workspace的某个子目录里进行下载与计算,至于其文件夹命名规则就很难琢磨了。
每次执行CI流程时,如果你想在自己的脚本中获知当前是什么分支,保存在什么目录等各式各样的信息,可以直接通过环境变量获知,jenkins会将这些环境信息放在环境变量里传给脚本,这方面的知识可以看一下访问本机部署的jenkins相关页面:http://localhost:8080/pipeline-syntax/globals#env。
Jenkinsfile支持2种语法,一种是Scripted Pipeline,采用Groovy语法,而我们用的叫做Declarative Pipeline,是一种jenkins专属的DSL,比较简单但缺乏Groovy脚本的强大灵活性。
我目前对jenkins的了解也就大概这些,它的核心功能集合并不复杂。
随便扯扯
每个公司的协作风格不同,虽然在Jenkins的玩法下能简单快速的实现一个自动化测试,编译,部署的流程,但是具体怎么做适合公司的现状是很难一概而论的。
公司一般有若干项目,项目间通过域名相互调用(中等规模公司并没有服务治理),假设采用SVN版本管理。
简单项目没那么多复杂的场景,各项目的成员共用dev分支开发,频繁提交,Jenkins自动部署到联调机验证。
(联调机上配置/etc/hosts,将所有服务的域名指向本地localhost,保证服务间调用均在本机完成)
开发完成提测合并test分支,Jenkins自动部署到测试机验证。测试完成合并trunk分支,Jenkins打包上预览机,最终发布上线。
一个稍显捉急的场景:比如某个新功能正在test测试,而一个紧急bugfix需要尽快上线,一般会怎么分支管理呢?我觉得一般会从trunk上拉一个临时分支进行修复,然后QA直接测试这个临时分支,问题是我们并没有环境来搭建这个临时分支(我们只有dev、test、trunk三套物理环境)供临时测试。
简单的应对方法是:手动把临时分支替换到test环境,尽快测试完成后切换回test分支,这也可以容忍。
一个更为捉急的场景:紧急的并不是bugfix,而是一个紧急的抽奖运营活动,这个测试需要花费1天的时间,替换test环境就会阻塞新功能的测试。
简单的应对方法是:如果新功能和运营活动没有冲突可以并存,那么把dev直接合到test分支,2个QA并行测试即可,最后再把临时分支合到trunk。
极端场景是:新功能和运营活动存在某种代码冲突(比如替换了基础库)难以共存,那么2个QA就无法并行测试。
现在QA一定会想:能不能搭个新的物理环境出来专门测试紧急需求?
好吧,被逼到绝境了,需求的本质也看得更加清楚了:能不能指定各个项目的分支&版本,搭建出一套完整的测试环境,而不影响其他测试环境?
这恐怕要涉及PAAS,配置中心,服务治理,各个举措才能实现了,欢迎大家交流。
另外一个议题是,公司一直有计划从svn迁移gitlab,其实两者都支持挑选commit进行代码合并,相关说明:git中只merge部分Commit,git log高级用法。
后续讨论
与留言区的朋友交流,他已在公司做了一套基于jenkins的流程。
主要思路是:
- 采用pipeline模式,jenkinsfile不关联到具体项目版本库,采用手动构建触发。
- jenkinsfile订制一系列通用发布流程,通过脚本/Groovy实现逻辑。
- 每次项目发布到测试/线上环境,可以手动编辑params配置参数(要发布哪个项目,哪个分支),并手动触发一次构建来实现发布。
- 可见,这种思路仅仅是利用jenkins的pipeline流程,而实际的代码下载,构建,部署都全部通过jenkinsfile自己实现。